Top 10 AWS Data Ingestion Tools for Seamless Data Pipelines
Summarize with Perplexity


Data ingestion is a crucial step in performing any data-driven task, such as data analytics and business intelligence initiatives. It lays the necessary groundwork required for smoother execution of subsequent processes like transformation and storage.
By using Amazon Web Services (AWS) tools for data ingestion, you can benefit from scalable infrastructure, reduced operational complexity, and faster time-to-insight. In this article, you will discover the top thirteen AWS data ingestion tools to help you build high-performance pipelines and facilitate quick data movement.
How AWS Data Ingestion Tools Work?
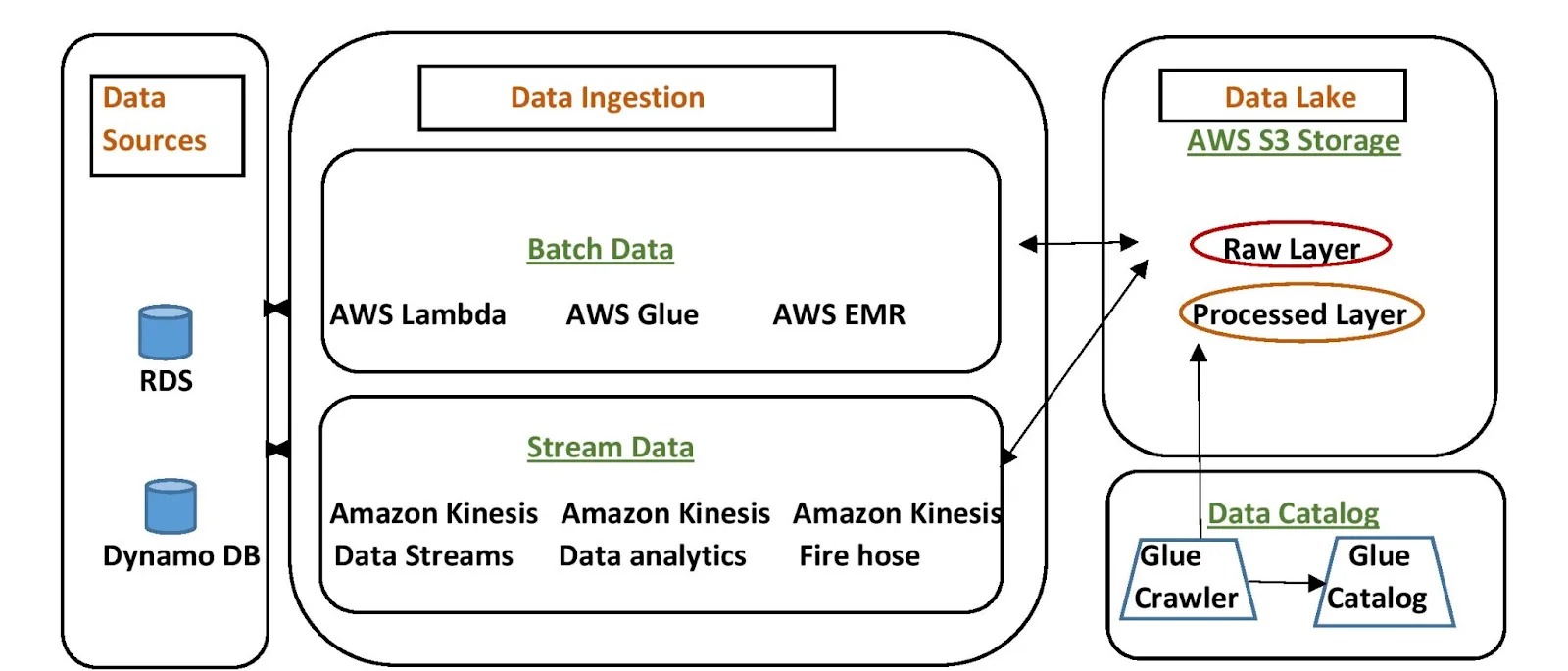
AWS data ingestion tools allow you to extract your data from sources like relational databases, IoT devices, or web applications to collect relevant information. You can either capture and process data in real-time using Amazon Kinesis or in large batches using AWS Snowball. Some tools even let you automate data movement and transformation.
The ingested data is then loaded into AWS storage solutions like Amazon S3 or Redshift. This dataflow ensures that raw data is efficiently shifted and organized for deeper analysis while maintaining scalability and speed.
10 AWS Data Ingestion Tools We Recommend
Data ingestion tools simplify the process of extracting and unifying varied data from multiple locations. These encompass IoT devices, downstream applications, file protocols, and on-premise storage centers. Here are the top ten AWS data ingestion tools that you can leverage for your organization’s smooth data transfer operations.
1. Airbyte
Airbyte is a reliable data movement platform that empowers you to extract structured, semi-structured, and unstructured data from dispersed sources. With its intuitive UI and no-code pre-built 600+ connectors, you can copy this data into databases, data warehouses, or data lakes, including AWS services like Datalake, Redshift, S3, Kinesis, DynamoDB, and more.
Apart from these pre-built connectors, you can build custom ones using Connector Builder. This solution features an AI assistant that prefills the configuration fields and provides intelligent suggestions for fine-tuning the development process. For advanced customization, Airbyte offers flexible options to build pipelines through its API, Terraform Provider, and PyAirbyte.
Key Features
- 600+ pre-built connectors (structured, semi-structured, unstructured).
- No-code UI + Connector Builder for custom connectors.
- Integrates with AWS services like Redshift, S3, DynamoDB, Kinesis.
- AI assistant for connector setup.
- API, Terraform Provider, and PyAirbyte for advanced customization.
2. AWS Snowball Edge
AWS Snowball is a service that helps you quickly migrate large volumes of data between Amazon S3 and on-premises data storage locations. Snowball Edge is a type of pre-configured Snowball device that can conduct local processing and edge-computing workloads within isolated operating environments. This tool is most useful when you want to move data from remote or disconnected locations, such as an oil and gas rig, mining sites, and moving vehicles like ships.
Key Features
- Physical device for secure offline data migration.
- Edge-computing and local data processing support.
- Rugged design for remote/disconnected environments.
- Integration with Amazon S3.
3. AWS Database Migration Service (DMS)
AWS Database Migration Service (DMS) is one of the most popular AWS Migration Tools available. Using it, you can migrate data from a database to an AWS service. The database can be either on-premises, in an Amazon RDS DB instance, or in your EC2 instance.
With AWS DMS, you get the flexibility to conduct data integration for several homogeneous and heterogeneous database migrations, such as Oracle, PostgreSQL, MongoDB, and more. This AWS ingestion tool helps you maintain high data availability and minimal downtime even while transferring terabyte-size datasets. You only have to pay for the compute resources and additional log storage that you use during data movement.
Key Features
- Fully managed database migration service.
- Supports homogeneous & heterogeneous migrations (e.g., Oracle → PostgreSQL).
- Minimal downtime during migration.
- Pay-as-you-go pricing.
4. AWS Transfer Family
AWS Transfer Family lets you securely store data in Amazon Simple Storage Service or Amazon Elastic File System. Through this AWS data ingestion tool, you can simplify data transfer from specified workflows into AWS. It facilitates secure and reliable transfer through Secure File Transfer Protocol (SFTP), File Transfer Protocol Secure (FTPS), File Transfer Protocol (FTP), and Applicability Statement 2 (AS2). When using the AWS Transfer family web app, you must keep in mind that there are limitations for maximum search results and breadth per query.
Key Features
- Managed SFTP, FTPS, FTP, and AS2 service.
- Integrates with S3 and EFS for storage.
- Scalable and compliant with industry protocols.
- Supports role-based access control.
5. Amazon OpenSearch Ingestion
A subset of Amazon OpenSearch Service, OpenSearch Ingestion is a fully managed serverless data collector. It enables you to deliver real-time log, metric, and trace data to OpenSearch Service and Serverless collections without relying on Logstash and Jaeger. With this AWS data collection tool, you can provision ingestion pipelines directly within the AWS Management Console. You do not have to look after the management and scaling of software and servers. OpenSearch Ingestion automatically provisions and delivers the data to your specified domain.
Key Features
- Fully managed, serverless log and metrics ingestion.
- Integrates with OpenSearch Service and Serverless.
- Eliminates need for Logstash/Jaeger.
- Real-time data delivery.
6. AWS Data Pipeline
AWS Data Pipeline is a web service that allows you to define data-driven workflows along with the parameters for transforming your data. In this tool, each new task is dependent on the successful completion of the previous tasks. You must create Amazon EC2 instances to schedule pipelines and run tasks on the AWS Data Pipeline. However, this service is currently under maintenance, making it unavailable for new customers.
Key Features
- Workflow orchestration for data movement & transformation.
- Supports both AWS and on-premises data sources.
- Dependency-based task execution.
- Integrates with EC2 and EMR.
7. AWS IoT Core
AWS IoT provides you with cloud services that enable you to connect your IoT devices to AWS cloud services or any other devices. The IoT Core message broker supports devices and clients that use MQTT, HTTP protocols, and MQTT over WSS protocols to publish messages. Using the AWS IoT Core for LoRaWAN, you can manage wireless low-power, long-range Wide Area Network (LoRaWAN) devices with ease.
Key Features
- Connects IoT devices to AWS securely.
- Supports MQTT, HTTP, and MQTT over WSS.
- LoRaWAN device management.
- Device authentication & rule engine for routing.
8. Fivetran
Fivetran is one of the widely used AWS ETL tools that offers pre-configured connectors to move data into AWS services, like Amazon Redshift, S3, and others. You can also deploy Fivetran through the AWS Marketplace. Additionally, Fivetran supports AWS PrivateLink, which enables security between data sources and AWS destinations.
Key Features
- Fully managed ELT platform.
- Pre-built connectors for Redshift, S3, and other AWS services.
- AWS Marketplace deployment available.
- Supports AWS PrivateLink for secure data transfer.
9. AWS Direct Connect
AWS Direct Connect allows you to establish a direct connection from an on-premises network to more than one VPC. The tool utilizes industry-standard 802.1Q VLANs to help you integrate with Amazon VPCs through private IP addresses. You can configure VLANs through three different types of virtual interfaces (VIFs). AWS Direct Connect provides you with two types of connections: Dedicated and Hosted. However, this AWS tool is not encrypted by default.
Key Features
- Dedicated network connection to AWS.
- Supports multiple virtual interfaces (VIFs).
- Integrates with multiple VPCs.
- Lower latency than internet connections.
10. AWS Storage Gateway
AWS Storage Gateway is a hybrid cloud storage tool that lets you integrate your existing on-premises infrastructure with AWS cloud storage. If you are already working with Windows workloads, you can leverage Storage Gateway to store and access data. This can be done by using native Windows protocols, SMB and NFS. AWS Storage Gateway offers four tools: Amazon S3 File Gateway, FSx File Gateway, Tape Gateway, and Volume Gateway. The former two are most often used with Microsoft workloads.
Key Features
- Hybrid cloud storage integration.
- Supports SMB, NFS, iSCSI protocols.
- Multiple modes: File Gateway, Volume Gateway, Tape Gateway.
- Works with Windows workloads.
How to Choose the Right AWS Data Ingestion Tool
Selecting the right data ingestion tool for AWS isn’t just about picking the one with the most features — it’s about aligning capabilities with your specific data sources, workloads, and business needs.
1. Identify Your Data Sources & Formats
- What are you ingesting? (Structured DB tables, logs, IoT sensor data, files, streaming events, etc.)
- Tools like AWS DMS excel at database migrations, while AWS IoT Core is built for device telemetry, and AWS Snowball Edge is designed for bulk offline transfers.
2. Determine Ingestion Frequency & Latency Requirements
- Real-time ingestion (e.g., log analytics, fraud detection) → Consider Amazon OpenSearch Ingestion, Airbyte (CDC mode), or Kinesis (if in scope).
- Batch ingestion (e.g., nightly ETL, archive uploads) → Tools like AWS Data Pipeline or AWS Transfer Family may be more cost-effective.
3. Evaluate Integration with Existing AWS Services
- If your workflow heavily relies on Redshift, S3, or EMR, choose a tool with native AWS integration.
- Open-source tools like Airbyte or managed solutions like Fivetran can also integrate, but may require extra configuration.
4. Consider Scalability & Data Volume
- For petabyte-scale transfers without network dependency, use AWS Snowball Edge or AWS Direct Connect.
- For high-velocity streaming, ensure the service supports horizontal scaling without data loss.
5. Security, Compliance & Governance
- Look for features like encryption in transit and at rest, PrivateLink support, and compliance with GDPR/HIPAA if relevant.
- Managed services like Fivetran or AWS-native ingestion tools may simplify compliance.
6. Budget & Total Cost of Ownership
- Pricing varies — AWS-native services often charge per GB or per request, while third-party tools may have subscription tiers.
- Factor in data transfer costs, storage, and processing fees, not just tool licensing.
7. Ease of Management
- Fully managed services (e.g., Fivetran, AWS DMS) reduce operational overhead.
- Self-managed/open-source tools (e.g., Airbyte OSS) offer flexibility but require infrastructure management.
How AWS Data Ingestion Tools Work?
AWS data ingestion tools allow you to extract your data from sources like relational databases, IoT devices, or web applications to collect relevant information. You can either capture and process data in real-time using Amazon Kinesis or in large batches using AWS Snowball. Some tools even let you automate data movement and transformation.
The ingested data is then loaded into AWS storage solutions like Amazon S3 or Redshift. This dataflow ensures that raw data is efficiently shifted and organized for deeper analysis while maintaining scalability and speed.
AWS Data Ingestion Tools: Use Cases
AWS data ingestion tools can empower your organization to support multiple use cases and bring out the true potential of its data assets. Here are some ways you can leverage these tools:
- Migrating Databases to AWS Cloud: You can utilize AWS DMS to migrate your on-premises databases to AWS-managed services with minimal downtime.
- Ingesting IoT Data for Monitoring: AWS IoT Core allows you to collect, ingest, and manage data from IoT devices for applications like smart home monitoring or industrial systems.
- Data Transfer for AI/ML Training: You can use AWS DataSync and Snowball to ingest massive datasets into AWS for training machine learning models on Amazon SageMaker.
How to Pick The Right AWS Data Ingestion Tool?
Choosing the right AWS data ingestion tool depends heavily on your organization’s specific requirements. Here's a breakdown of certain factors that you can consider:
- Data Sources: You should identify the types of sources (streaming data, IoT devices, SaaS applications) you work with, as different tools are optimized for different source types.
- Transformation Needs: Based on the quality of your incoming data, you need to decide whether to transform it during the ingestion process. This helps you further categorize the tools depending on the availability of built-in transformation capabilities.
- Data Destination: Knowing which AWS platform (S3, Redshift, or DynamoDB) you will utilize for downstream data processing can guide your choice of ingestion tool. The tool you select must integrate with your target destination effortlessly.
- Ease of Use: You should consider the tool’s complexity, its learning curve, and your team’s expertise. Opting for a platform that is easy to use and manage can be ideal for your organization.
- Cost: By evaluating each tool’s data transfer, processing, and storage costs, you can achieve your performance requirements while adhering to budget constraints.
Closing Thoughts
AWS data ingestion tools are reliable and budget-friendly options if your organization is deeply invested or dependent on Amazon. The AWS ecosystem provides you with a multitude of options to collect, process, and manage different types of data. Once you consolidate your data, you can ensure its quality, security, and validity for all operations in your organization. You can even leverage AWS ML and data processing capabilities, data centers across regions, generative AI, and foundation models to develop robust customer solutions.
Frequently asked questions
1. What is AWS data ingestion?
AWS data ingestion is the process of collecting and importing data from multiple sources—such as databases, SaaS applications, IoT devices, and logs—into AWS services for processing, storage, and analysis. Tools like Amazon Kinesis, AWS Glue, and AWS DataSync help streamline this process.
2. Which AWS services are best for real-time data ingestion?
Amazon Kinesis Data Streams and Kinesis Data Firehose are ideal for real-time ingestion, enabling you to capture and process data from streaming sources like application logs, clickstreams, and IoT devices with minimal latency.
3. Can AWS handle batch and streaming ingestion in the same workflow?
Yes. AWS allows you to combine batch ingestion with services like AWS Glue or AWS Data Pipeline and streaming ingestion via Kinesis or Amazon MSK. Many organizations use a hybrid approach to process both historical and real-time data together.
4. How does AWS ensure data security during ingestion?
AWS provides multiple layers of security, including encryption at rest and in transit, IAM-based access controls, VPC endpoints, and integration with AWS Key Management Service (KMS) to protect sensitive data during ingestion.
5. What factors should I consider when choosing an AWS data ingestion tool?
Consider data volume, ingestion frequency (real-time vs. batch), integration requirements, cost, and scalability. For example, Kinesis is better for continuous streams, while AWS Glue suits scheduled, large-scale ETL jobs.
Suggested Reads
What should you do next?
Hope you enjoyed the reading. Here are the 3 ways we can help you in your data journey:



.png)
Frequently Asked Questions
What is ETL?
ETL, an acronym for Extract, Transform, Load, is a vital data integration process. It involves extracting data from diverse sources, transforming it into a usable format, and loading it into a database, data warehouse or data lake. This process enables meaningful data analysis, enhancing business intelligence.
This can be done by building a data pipeline manually, usually a Python script (you can leverage a tool as Apache Airflow for this). This process can take more than a full week of development. Or it can be done in minutes on Airbyte in three easy steps: set it up as a source, choose a destination among 50 available off the shelf, and define which data you want to transfer and how frequently.
The most prominent ETL tools to extract data include: Airbyte, Fivetran, StitchData, Matillion, and Talend Data Integration. These ETL and ELT tools help in extracting data from various sources (APIs, databases, and more), transforming it efficiently, and loading it into a database, data warehouse or data lake, enhancing data management capabilities.
What is ELT?
ELT, standing for Extract, Load, Transform, is a modern take on the traditional ETL data integration process. In ELT, data is first extracted from various sources, loaded directly into a data warehouse, and then transformed. This approach enhances data processing speed, analytical flexibility and autonomy.
Difference between ETL and ELT?
ETL and ELT are critical data integration strategies with key differences. ETL (Extract, Transform, Load) transforms data before loading, ideal for structured data. In contrast, ELT (Extract, Load, Transform) loads data before transformation, perfect for processing large, diverse data sets in modern data warehouses. ELT is becoming the new standard as it offers a lot more flexibility and autonomy to data analysts.