Semantic Search vs Vector Search: Key Differences

✨ AI Generated Summary
The exponential growth of unstructured data has rendered traditional keyword search inadequate, driving adoption of semantic and vector search technologies that understand context, intent, and semantic relationships. Semantic search leverages NLP and knowledge graphs for precise, intent-driven retrieval, while vector search uses embeddings and similarity algorithms for scalable, multimodal data handling.
- Semantic search excels in nuanced query understanding and domain-specific applications but requires complex NLP processing.
- Vector search offers faster, scalable retrieval across massive datasets and supports diverse data types like images and audio.
- Hybrid search systems combine both methods to balance accuracy and performance, supported by infrastructure that manages text and vector indexes concurrently.
- Platforms like Airbyte facilitate embedding management and integration with vector databases, automating workflows and reducing operational overhead.
- Key considerations include privacy, bias, computational costs, and scalability aligned with application requirements and data volumes.
The landscape of information retrieval faces an unprecedented crisis as organizations grapple with the exponential growth of unstructured data. Traditional keyword-based search methods have become inadequate for navigating this complex data ecosystem, where context, intent, and semantic relationships matter more than exact word matches.
The emergence of large language models and AI-driven applications has created both extraordinary opportunities and formidable technical challenges, forcing data professionals to rethink their entire approach to information discovery and knowledge extraction. Modern enterprises are discovering that their existing search infrastructures cannot handle the nuanced requirements of AI applications, where understanding context and meaning is essential for delivering relevant results.
This technological inflection point has accelerated the adoption of semantic search and vector search technologies, each offering distinct advantages for different use cases while presenting unique implementation challenges that data teams must carefully navigate.
What Are the Core Principles Behind Semantic Search Technology?
Semantic search represents an advanced information-retrieval technique that leverages natural language processing (NLP) and machine learning to understand the intent and context behind user queries. Rather than relying on literal keyword matching, semantic search analyzes the relationships between words and concepts to deliver contextually relevant results.
This approach proves particularly valuable for handling ambiguous or complex queries where multiple interpretations are possible, enabling more intuitive and effective information-discovery experiences.
The technological foundation of semantic search rests on sophisticated NLP capabilities—tokenization, part-of-speech tagging, and syntactic analysis—to decompose queries into their fundamental components while preserving the relationships between different elements. This linguistic analysis extends beyond simple word identification to encompass understanding of grammatical structures, semantic relationships, and contextual dependencies that give meaning to human communication.
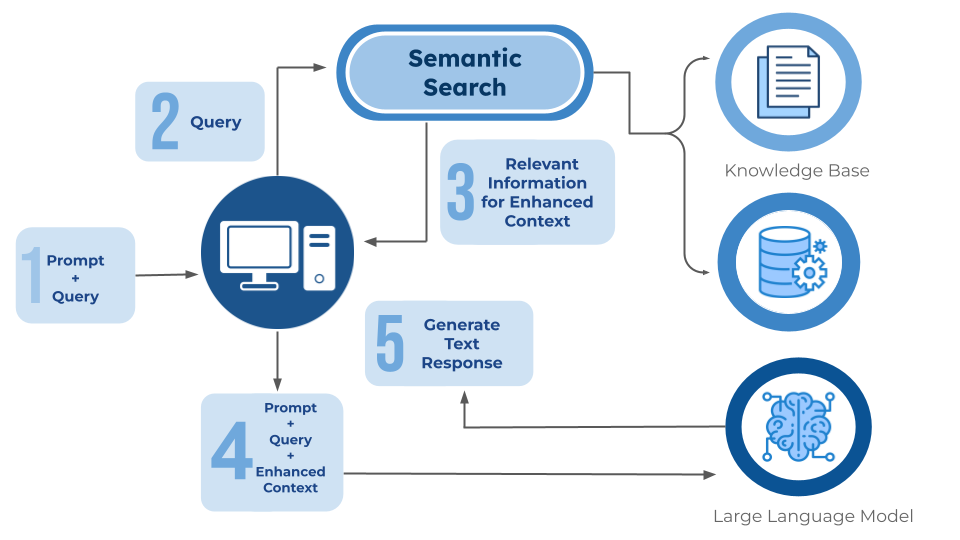
How Does Semantic Search Process User Queries?
Understanding query processing represents the first critical stage in semantic search implementation. The search engine utilizes advanced NLP techniques, including tokenization and part-of-speech tagging, to identify relationships between words and concepts within user queries.
Words are frequently transformed into word embeddings—mathematical representations that group semantically similar terms together in high-dimensional vector spaces. This transformation enables the system to understand that terms like "automobile" and "car" represent the same concept, even when they share no literal text similarities.
Entity recognition serves as another fundamental component, where the system identifies and categorizes key entities such as people, places, organizations, and concepts within queries. This capability enables the search system to understand not just individual words but their roles and relationships within the broader context of the query.
Advanced entity-recognition systems can distinguish between different meanings of the same word based on surrounding context. For example, they can differentiate between "Apple" the technology company and "apple" the fruit based on contextual clues.
What Makes Content Matching More Effective?
Content matching processes involve sophisticated algorithms that compare user queries with indexed content through semantic relationships rather than simple keyword matching. The system analyzes the overall topic, sentiment, and meaning of both the query and potential results.
This approach enables the search system to identify relevant content even when exact keywords are not present. The matching process goes beyond surface-level text comparison to understand the underlying concepts and themes that connect queries with relevant information.
Contextual analysis enhances search accuracy by incorporating additional factors such as user location, search history, device type, and temporal context. This personalization enables the system to deliver results that are not only semantically relevant but also practically useful for individual users.
The ranking and retrieval process leverages knowledge graphs and sophisticated scoring algorithms to order results based on relevance and user intent.
What Are the Primary Advantages of Semantic Search?
Enhanced user experience through faster, more relevant results and direct answers to complex questions represents the most immediate benefit. Users can express their information needs in natural language without worrying about exact keyword matching.
Accurate information retrieval via comprehensive knowledge graphs that capture relationships between entities and concepts ensures that search results reflect true semantic relevance rather than superficial text matching.
Adaptability allows NLP models to rapidly learn new languages, terminology, and evolving usage patterns, making them valuable for domain-specific applications where specialized vocabulary is essential.
What Limitations Should Organizations Consider?
Privacy concerns arise due to reliance on user data including location, history, and preferences for contextual enhancement. Organizations must balance personalization benefits with user privacy expectations and regulatory requirements.
Algorithm bias stemming from skewed training data can lead to unfair or inaccurate results for certain user groups or query types. Regular auditing and diverse training data help mitigate these risks.
Performance limitations for complex queries demand significant compute resources, potentially impacting response times and operational costs for high-volume applications.
How Does Vector Search Transform Information Retrieval?
Vector search enables organizations to understand the meaning and context of diverse unstructured data types—including text, images, audio, and video—through numerical representations called vector embeddings. Using approximate nearest-neighbor techniques, vector search can capture semantic relationships and conceptual similarities that traditional keyword searches miss.
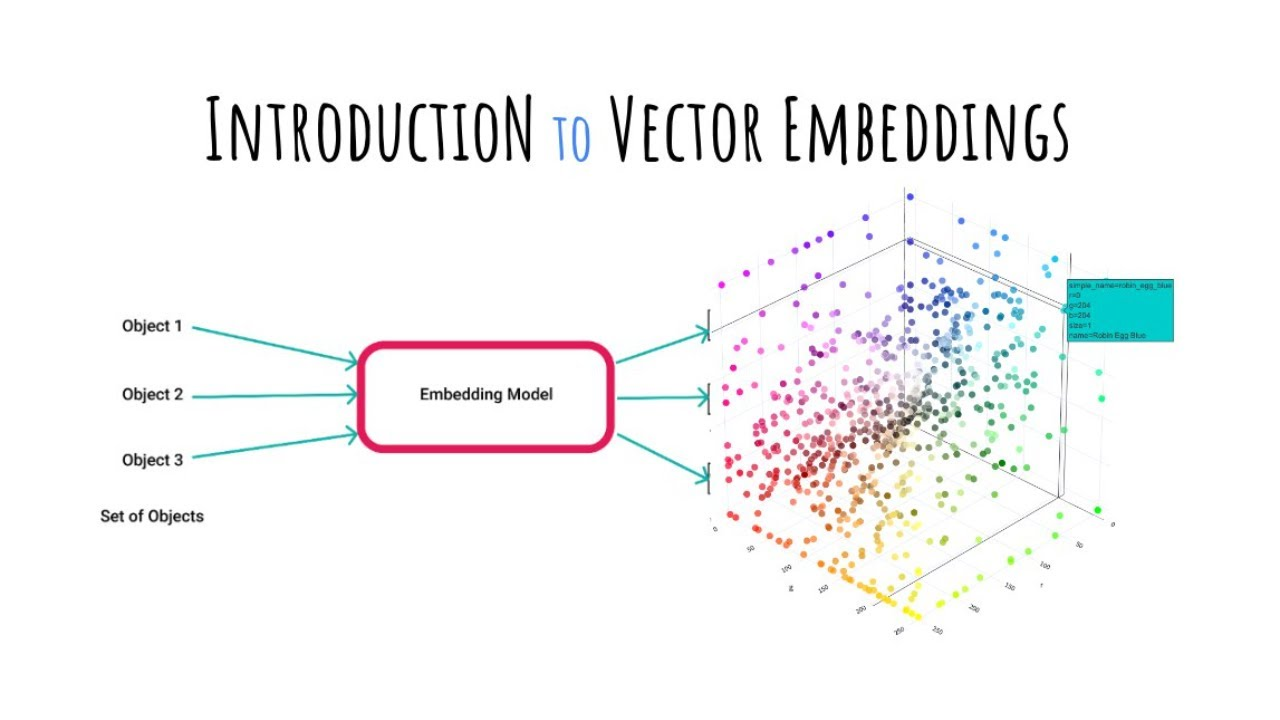
How Does the Vector Search Process Function?
Embedding generation converts diverse data items into mathematical vectors capturing key attributes and semantic meaning. This process transforms unstructured data into a format that enables mathematical comparison and similarity calculation.
The quality of embeddings directly impacts search accuracy, making the choice of embedding model crucial for specific use cases and data types. Different embedding models excel at different tasks, from general text understanding to specialized domain applications.
Indexing and optimization organize embeddings for efficient retrieval using techniques like hierarchical clustering and specialized index structures. These techniques enable fast similarity searches across millions or billions of vectors without exhaustive comparison.
Similarity search algorithms including k-nearest neighbor and approximate nearest neighbor compare embeddings with distance metrics such as cosine similarity or Euclidean distance. These algorithms balance accuracy with speed, enabling real-time search across large vector collections.
What Advantages Does Vector Search Provide?
Multilingual capabilities emerge naturally as embeddings preserve meaning across languages, enabling cross-lingual search without explicit translation. This capability proves valuable for global organizations managing content in multiple languages.
Context awareness allows the system to retrieve semantically similar content even with different terminology or phrasing. Users can find relevant information regardless of the specific words they choose to express their needs.
Scalability for massive datasets becomes achievable through optimized algorithms and hardware acceleration, enabling search across petabyte-scale collections with reasonable response times.
What Challenges Must Organizations Address?
Data maintenance requires keeping vector indexes fresh and consistent as underlying data changes. This ongoing process demands careful coordination between data updates and index refresh cycles.
Specialized data challenges arise in jargon-heavy domains including healthcare, legal, and scientific applications where general-purpose embedding models may not capture domain-specific meanings accurately.
Higher operating costs result from compute-intensive embedding generation and storage requirements, particularly for large-scale deployments with frequent updates.
How Can Airbyte Optimize Vector Embedding Management?
Airbyte is an AI-powered data-integration platform offering 600+ connectors, including destinations for vector databases such as Chroma, Milvus, Pinecone, and Weaviate. The platform integrates with frameworks like LangChain and LlamaIndex, supports embedding generation via OpenAI, Cohere, and Anthropic.
Airbyte automates chunking and indexing workflows, keeping embeddings current without manual intervention. This automation reduces operational overhead while ensuring vector indexes remain synchronized with source data changes.
The platform handles complex data transformation requirements that arise when preparing diverse data types for vector embedding generation. This capability proves essential for organizations managing mixed content types across multiple sources.
What Are the Key Differences Between Semantic Search vs Vector Search?
How Do Their Architectures Differ?
Semantic search emphasizes linguistic understanding through tokenization and embedding models that capture semantic relationships. While some systems may integrate syntactic analysis, intent detection, or knowledge graph infrastructure, these are not strictly required in all semantic search implementations.
Vector search relies on mathematical similarity calculations in high-dimensional space, enabling multimodal retrieval across different data types. This mathematical approach simplifies architecture while supporting diverse content formats.
The architectural differences reflect fundamental trade-offs between linguistic precision and computational efficiency, with each approach optimized for different use cases and performance requirements.
Which Approach Delivers Better Performance?
Vector search usually outperforms semantic search on very large datasets by trading minimal accuracy for significant speed via approximate methods. The mathematical nature of vector comparison enables highly optimized algorithms and hardware acceleration.
Semantic search may deliver superior precision for nuanced queries where deep contextual understanding proves essential. Complex reasoning tasks often benefit from the linguistic sophistication that semantic search provides.
Performance considerations must account for both query response time and result relevance, as the optimal choice depends on specific application requirements and user expectations.
How Do They Compare in Scalability?
Vector search engines scale more naturally due to approximate nearest neighbor indexing and distributed vector operations. The mathematical operations can be parallelized effectively across multiple computing resources.
Semantic search scalability depends on NLP complexity and knowledge-graph traversal requirements. Complex linguistic processing can become a bottleneck as query volume increases.
Scalability planning must consider both horizontal scaling capabilities and the computational requirements of different search approaches under various load conditions.
What Are Their Primary Use Cases?
Semantic search excels in customer support chatbots where understanding user intent and context proves crucial for providing accurate responses. While context-aware recommendation systems benefit from various advanced modeling techniques for handling contextual data, semantic understanding can support related tasks such as user query interpretation.
Vector search proves ideal for image and video search applications, real-time fraud detection, anomaly detection, and visual product discovery. These use cases leverage vector search's ability to find similar patterns across diverse data types.
The choice between approaches often depends on the specific nature of the data, query types, and performance requirements of individual applications.
How Can Organizations Implement Advanced Hybrid Search Methodologies?
Hybrid search combines keyword matching, semantic understanding, and vector similarity in parallel pipelines. This approach leverages the strengths of each method while mitigating individual weaknesses.
Results from different search methods are merged through score normalization or advanced fusion techniques including reciprocal rank fusion and two-stage retrieval. These techniques ensure that results from different approaches contribute appropriately to final rankings.
What Infrastructure Requirements Support Hybrid Implementation?
Successful hybrid implementations require schemas that store both text fields and vector fields within the same data structures. This dual storage enables simultaneous querying across different search methodologies.
Real-time pipelines must refresh both keyword indexes and vector indexes simultaneously to maintain consistency across search approaches. Coordination between different indexing processes becomes crucial for maintaining data accuracy.
Resource management must balance NLP workloads with vector-calculation demands, often requiring separate computational resources optimized for different types of processing.
What Performance Optimization and Scaling Strategies Are Most Effective?
Real-time index management with incremental vector updates using techniques like HNSW insertions enables continuous data freshness without complete index rebuilds. This approach maintains search accuracy while minimizing computational overhead.
Dynamic cloud scaling via container orchestration using Kubernetes allows independent scaling of NLP and vector components based on demand patterns. This flexibility optimizes resource utilization and cost management.
How Can Organizations Optimize Storage and Retrieval?
Multi-vector retrieval and product quantization techniques compress large embedding sets while maintaining search quality. These approaches reduce storage costs and improve query performance for large-scale deployments.
Hybrid storage architectures mix in-memory vectors for frequently accessed data with cheaper persistent tiers for archival content. This tiered approach balances performance with cost optimization.
Edge and distributed search deployments reduce latency across geographic regions by positioning search capabilities closer to users. This distribution improves user experience while managing network costs.
What Monitoring Approaches Ensure Optimal Performance?
Continuous monitoring frameworks track query latency, relevance metrics, and resource consumption across all search components. This visibility enables proactive optimization and capacity planning.
Performance baselines help identify degradation before it impacts user experience, enabling preventive maintenance and optimization adjustments.
What Real-World Applications Demonstrate These Technologies?
How Is Semantic Search Applied in Practice?
Healthcare organizations use semantic search for patient-similarity analysis across medical records and research literature. This application helps identify treatment patterns and research connections that improve patient care.
Music streaming platforms leverage semantic search for track recommendations based on mood, tempo, and lyrical themes. Users can discover music through natural language descriptions rather than specific artist or song names.
Legal research systems use semantic search to find relevant case law and legal precedents based on conceptual similarity rather than exact keyword matches.
Where Does Vector Search Excel in Real Applications?
Financial services implement vector search for fraud detection by modeling normal versus anomalous transaction vectors. This approach identifies suspicious patterns that traditional rule-based systems might miss.
Autonomous vehicles use vector search for real-time sensor-data comparison enabling obstacle recognition and path planning. The speed and accuracy of vector comparison prove essential for safety-critical applications.
E-commerce platforms deploy vector search for visual product discovery from uploaded images. Customers can find similar products by uploading photos rather than describing items in text.
What Should Organizations Consider When Choosing Between These Approaches?
Semantic search proves ideal when deep contextual understanding and precision are paramount for application success. Applications requiring nuanced interpretation of user intent benefit most from semantic approaches.
Vector search excels when scalability, multimodal data support, and fast similarity matching are critical requirements. Large-scale applications with diverse content types often favor vector search implementations.
Hybrid search frequently provides optimal results by balancing accuracy and performance across different use cases. This approach allows organizations to leverage multiple search methodologies based on specific query characteristics.
What Factors Should Drive Technology Selection?
Data variety and volume considerations impact the feasibility and cost of different search approaches. Vector search generally scales better with data growth, while semantic search provides better precision for complex queries.
Query complexity and latency requirements determine which approach can meet user expectations for response time and result quality. Real-time applications often favor vector search for speed advantages.
Existing infrastructure and budget constraints influence implementation feasibility and ongoing operational costs. Organizations must consider both initial implementation costs and long-term maintenance requirements.
Long-term scalability goals help ensure that chosen approaches can grow with business needs and data volumes over time.
Conclusion
Semantic search and vector search each address the limitations of traditional keyword-based retrieval by introducing context, meaning, and similarity into how information is discovered. Semantic search excels at understanding user intent and nuanced queries, while vector search delivers scalable, multimodal retrieval across massive datasets. In practice, many organizations find the greatest value in hybrid approaches that combine both methods, balancing precision with performance.
As enterprises continue to generate and rely on vast amounts of unstructured data, adopting these advanced search technologies will be essential for unlocking deeper insights, powering AI-driven applications, and ensuring information remains accessible and actionable at scale.
Frequently Asked Questions
What is the main difference between semantic search and vector search?
Semantic search interprets meaning and intent via NLP and knowledge graphs; vector search finds similar content through numerical proximity in high-dimensional space.
Can semantic search and vector search be used together?
Yes. Hybrid systems often outperform single-method approaches by combining contextual understanding with efficient similarity matching.
Which approach is better for large-scale applications?
Vector search generally scales better for petabyte-scale datasets, though choice depends on accuracy requirements and query complexity.
What are the computational requirements for each approach?
Semantic search requires significant NLP processing and knowledge-graph maintenance; vector search demands compute for embedding generation and similarity calculations.
How do these technologies integrate with existing data infrastructure?
Semantic search integrates with NLP pipelines and knowledge-graph stores; vector search leverages specialized vector databases. Integration platforms like Airbyte provide connectors for both.
.webp)