How to Use API in Python with Example (Python API Tutorial)

✨ AI Generated Summary
Python enables efficient interaction with APIs through libraries like requests and httpx, facilitating data extraction, transformation, and advanced analytics. Key concepts include understanding API endpoints, HTTP methods, status codes, authentication (JWT, OAuth 2.0), and security best practices such as input validation and threat detection. Modern API development emphasizes resilience with error handling patterns (circuit breakers, retries), asynchronous programming for performance, real-time communication via WebSockets and Server-Sent Events, webhook integration, and hybrid architectures combining multiple protocols for scalable, production-ready systems.
Python is a robust programming language used by developers to interact with different APIs. It provides advanced functionalities, allowing you to extract raw data from various applications and perform complex transformations to generate actionable insights.
Acting on these insights can be beneficial in improving business performance and enhancing customer experience. But how does one use Python to interact with APIs?
This article describes how to use APIs in Python and its advantages, with practical examples of extracting data using APIs to build data pipelines.
What Is an API and How Does It Work?
Application Programming Interface, or API, is a set of rules and regulations that highlight how different applications communicate with each other. Working as an intermediary state, an API facilitates the interactions between client and server.
Here, the client initiates a request, and the server delivers an appropriate response to the given request. By bridging the gap between the client and the server application, APIs streamline the exchange of information, increasing interoperability across applications.
API HTTP Methods

API HTTP methods are crucial elements for sending requests and receiving responses. Each HTTP request has a unique name and functionality associated with it that enables the transfer of information between different systems. Some of the most commonly used HTTP methods include GET, POST, PUT, and DELETE.
API Status Codes
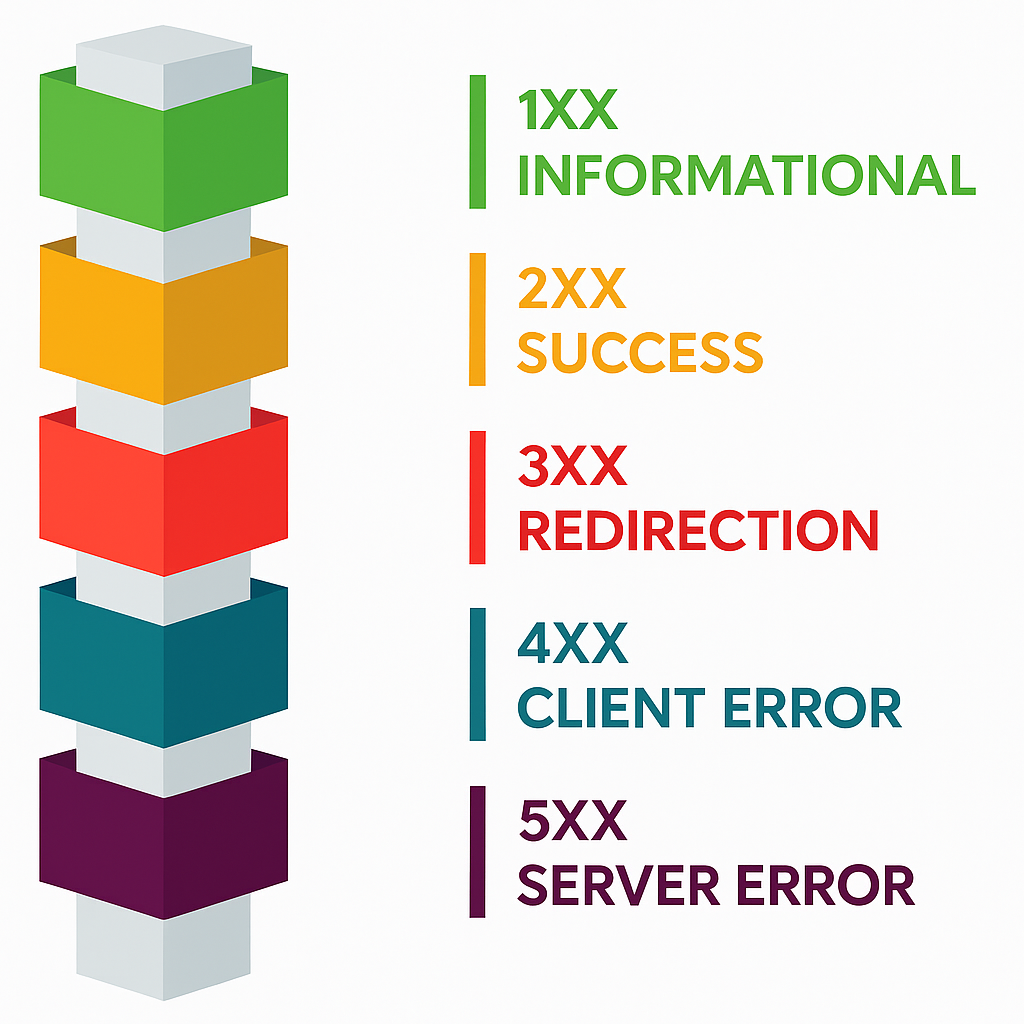
Whenever a request is made to an API, it responds with a status code indicating the outcome of the client request. The status code represents whether the request sent to the server was successful or not.
Some of the standard status codes associated with a GET request include 200, 301, 400, 401, 403, 404, and 503. Codes starting with 4 outline client-side errors, whereas codes beginning with 5 indicate server-side errors.
API Endpoints
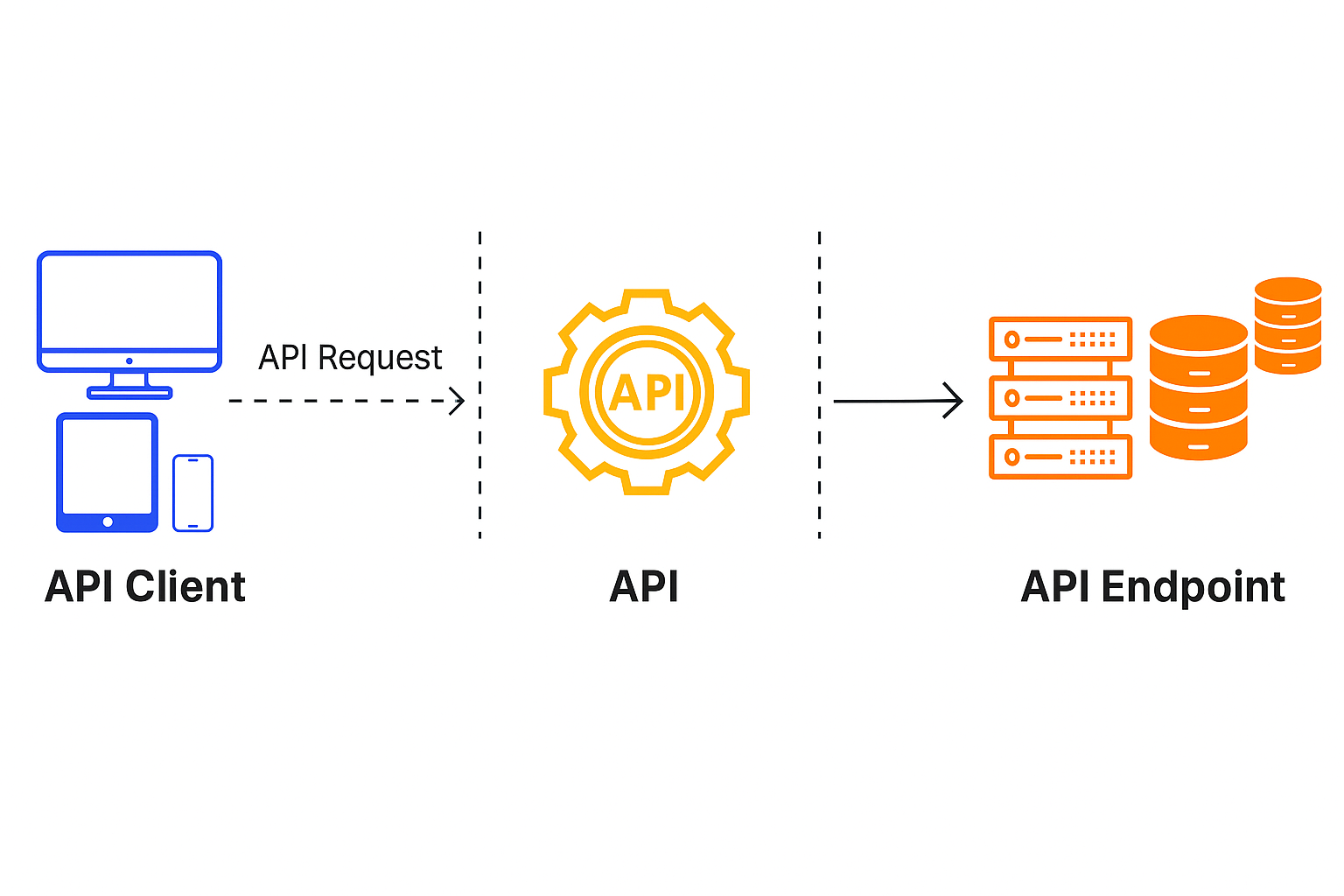
APIs allow access to specific data through multiple endpoints—addresses that correspond to specific functionality. Executing an HTTP method with the API endpoint details enables access to the data available at a particular location. Some endpoints might require only address parameters, while others might also require input fields.
Query Parameters
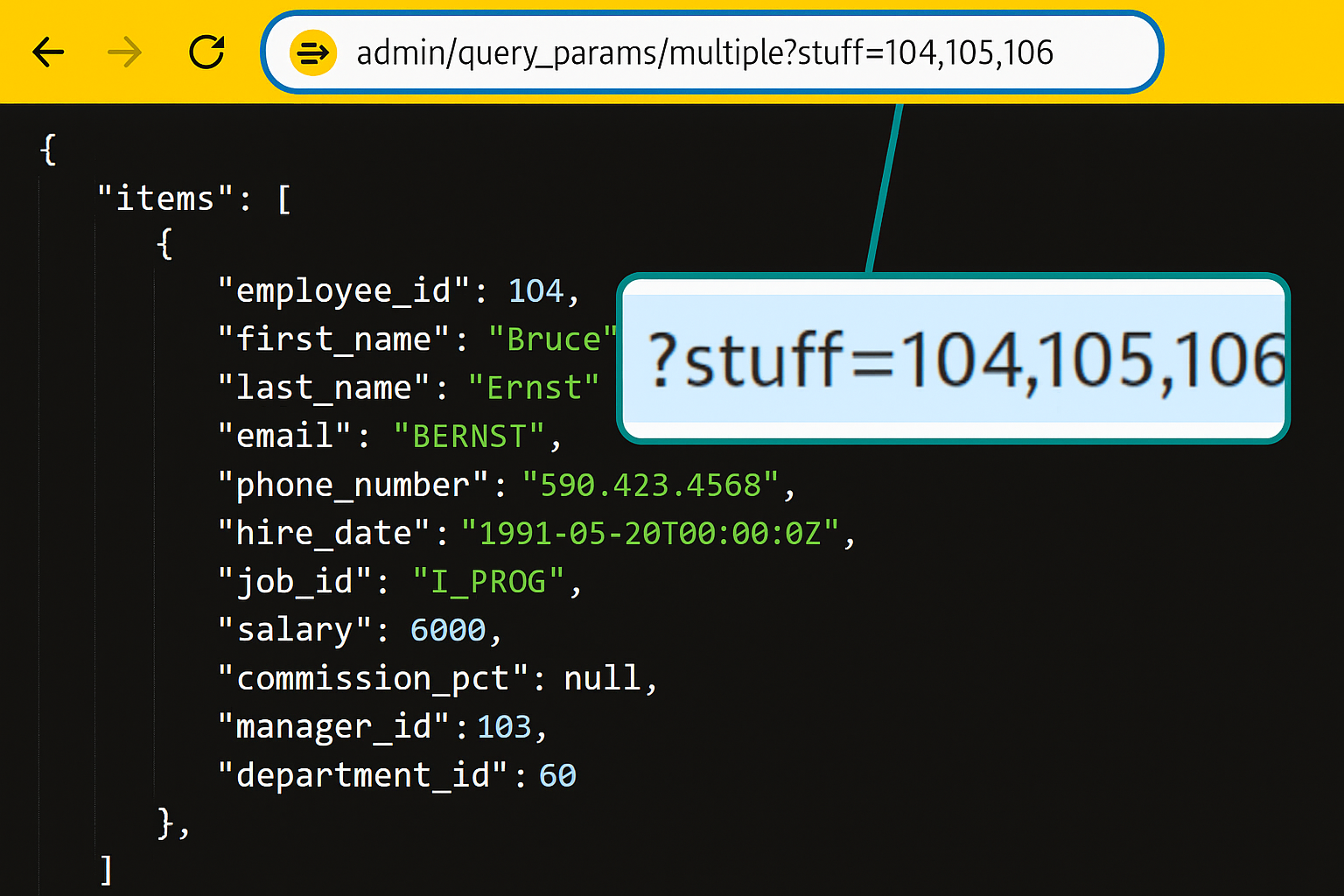
Query parameters filter and customize the data returned by an API. They appear at the end of the URL address of the API endpoint.
For example:
In this example, option=business&option=vegeterian are the query parameters. Specifying query parameters restricts the data to specific values depending on the requirements.
Why Should You Use APIs with Python?
Before getting started with how to use APIs in Python, you must first understand the why. Here are a few reasons demonstrating why working with APIs in Python is beneficial:
- Data Accessibility: One of the primary applications of leveraging Python for data engineering is extracting data from various sources and services. Python provides multiple libraries, including requests, urllib, and httpx, to work with APIs.
- Flexible Data Storage:Python data types enable you to store data effectively when working on analytics workloads.
- Advanced Analytics: Python offers robust libraries like scikit-learn and TensorFlow that can aid in creating powerful machine-learning models to answer complex questions.
- Parallel Processing: For use cases that require handling large amounts of data, you can leverage Python's multiprocessing module and modern asynchronous programming capabilities through
asyncioto optimize performance.
How Do You Use APIs in Python Step by Step?
Following a structured approach helps you effectively utilize Python with APIs to handle data from numerous sources. Let's explore the steps illustrating how to use APIs in Python.
1. Install Required Libraries
Python offers several libraries for making API requests:
- Requests: Simple and readable; supports synchronous requests.
- HTTPx: Supports both synchronous and asynchronous requests.
- Urllib: Part of the standard library.
Install with:
pip install requests
and import:
import requests
For async capabilities:
pip install httpx
2. Understand the API Documentation
Thoroughly review the API documentation to learn about endpoints, parameters, authentication, and response formats.
3. Set Up Authentication
For security, store keys in environment variables rather than in code.
4. Make the API Request
response = requests.get(url)print(response.status_code) # 200 means success
5. Handle JSON Responses
import jsondata = response.json()print(json.dumps(data, indent=2))
What Are Advanced Authentication and Security Best Practices for Python APIs?
Modern Python API development requires sophisticated authentication mechanisms that go beyond basic API key management to address enterprise-grade security requirements. Contemporary security practices emphasize zero-trust architecture principles, comprehensive input validation, and multi-layered security controls that protect against evolving threat vectors.
JWT Token-Based Authentication Systems
JSON Web Token authentication has become the standard for stateless API authentication in modern Python applications. JWT tokens enable secure information transmission between client and server without requiring server-side session storage, making them particularly valuable for distributed applications and microservices architectures. Python frameworks like FastAPI provide built-in JWT support that simplifies implementation while maintaining security best practices.
The implementation of JWT authentication involves creating tokens that contain encoded user information and permissions, signed with cryptographic keys to prevent tampering. Python applications can use libraries like PyJWT to handle token creation, validation, and refresh operations. Advanced implementations incorporate token expiration policies, refresh mechanisms, and secure key rotation procedures that balance security requirements with user experience considerations.

Security considerations for JWT implementation include proper secret key management, algorithm selection, and payload design that minimizes sensitive information exposure. Best practices emphasize using strong cryptographic algorithms, implementing secure key storage through environment variables or key management services, and designing token payloads that contain only necessary authorization information without exposing sensitive user data.
OAuth 2.0 and Modern Authorization Patterns
OAuth 2.0 provides standardized authorization frameworks for secure third-party API access without exposing user credentials. Python applications can implement OAuth flows using libraries like Authlib or requests-oauthlib that handle the complexity of authorization code flows, token exchange, and refresh operations. Modern OAuth implementations support multiple grant types including authorization code, client credentials, and device code flows for different use case requirements.
The authorization code flow represents the most secure OAuth implementation for web applications, involving browser-based user authorization followed by server-side token exchange. Python applications typically implement OAuth clients that redirect users to authorization servers, handle callback processing, and manage token storage for subsequent API requests. This approach enables secure integration with external services while maintaining user privacy and consent requirements.
Advanced OAuth patterns include PKCE (Proof Key for Code Exchange) for enhanced security in public clients and OpenID Connect for identity verification alongside authorization. Python developers should understand these extensions and implement appropriate patterns based on their specific security requirements and deployment environments.
Input Validation and Sanitization Strategies
Comprehensive input validation protects Python APIs against injection attacks, data corruption, and security vulnerabilities by ensuring all incoming data meets expected formats and constraints. Modern validation approaches use schema-based validation libraries like Pydantic or Marshmallow that provide declarative validation rules and automatic error handling for invalid inputs.
Data sanitization processes clean and normalize input data to prevent malicious content from reaching application logic or data storage systems. Python applications should implement whitelist approaches that accept only known-good input patterns rather than blacklist approaches that attempt to filter malicious content. This includes validating data types, string lengths, format patterns, and value ranges that align with business logic requirements.
Advanced validation patterns include context-aware validation that considers user permissions and request contexts when evaluating input data. Python applications can implement validation pipelines that apply different rules based on user roles, request sources, or data sensitivity levels, providing fine-grained protection against unauthorized data manipulation.
Security Monitoring and Threat Detection
Modern Python API security requires continuous monitoring and threat detection capabilities that identify suspicious activity patterns and potential security breaches. Security logging should capture authentication attempts, authorization failures, unusual request patterns, and data access events that provide visibility into potential threats while maintaining user privacy requirements.
Automated threat detection systems can analyze API usage patterns to identify anomalies that might indicate security issues, including unusual request volumes, geographic access patterns, or data access behaviors that deviate from normal user activities. Python applications can integrate with security information and event management systems to provide centralized security monitoring and incident response capabilities.
Rate limiting and abuse prevention mechanisms protect APIs from denial-of-service attacks and resource exhaustion by implementing intelligent request throttling based on client identity, request patterns, and system capacity. Modern rate limiting implementations use algorithms like token bucket or sliding window to provide fair resource allocation while preventing abuse that could impact legitimate users.
How Can You Implement Robust Error Handling and Performance Optimization?
Building resilient Python APIs requires comprehensive error handling strategies that gracefully manage failures while providing meaningful feedback to clients and system operators. Modern error handling approaches combine circuit breaker patterns, intelligent retry mechanisms, and context-aware error responses that maintain system stability under adverse conditions.
Circuit Breaker Pattern Implementation
Circuit breakers protect Python APIs from cascading failures by automatically detecting service degradation and providing fallback responses when downstream dependencies become unavailable. The pattern monitors failure rates and response times for external service calls, opening the circuit when thresholds are exceeded to prevent continued attempts that waste resources and increase latency.
Python implementations of circuit breaker patterns typically use decorators or context managers that wrap external service calls and maintain state information about service health. Libraries like PyBreaker provide robust circuit breaker functionality with configurable failure thresholds, recovery timeouts, and fallback mechanisms that integrate seamlessly with existing application code.
The three-state circuit breaker model includes closed, open, and half-open states that manage service interaction based on health status. The closed state represents normal operation with full service access, while the open state immediately returns fallback responses without attempting external calls. The half-open state provides controlled recovery testing by allowing limited requests to verify service restoration.
Advanced circuit breaker implementations can include sophisticated failure detection logic that considers response time thresholds, specific error codes, and business logic failures alongside simple connectivity issues. This nuanced approach to failure detection enables more intelligent protective behavior that distinguishes between different types of service degradation.
Comprehensive Retry Strategies and Exponential Backoff
Intelligent retry mechanisms enable Python APIs to recover from transient failures while avoiding overwhelming failing services with repeated requests. Exponential backoff algorithms provide increasing delays between retry attempts, allowing temporary issues to resolve while preventing retry storms that can worsen service degradation.
Python applications can implement retry strategies using libraries like backoff or custom decorators that provide configurable retry counts, delay algorithms, and exception filtering. Effective retry implementations distinguish between transient errors that might resolve with retries and permanent errors that should fail immediately without additional attempts.
Jitter addition to exponential backoff algorithms helps distribute retry attempts across time to prevent synchronized retry storms when multiple clients experience failures simultaneously. Python implementations can add random variations to calculated delay periods, reducing the likelihood of thundering herd problems that occur when many clients retry simultaneously.
Context-aware retry strategies consider the specific requirements of different API operations, adjusting retry behavior based on operation criticality, available time budgets, and current system load conditions. Critical operations might warrant more aggressive retry policies, while less important requests could use conservative approaches that minimize resource consumption.
Asynchronous Programming and Performance Optimization
Modern Python API development leverages asynchronous programming patterns to achieve high concurrency and improved resource utilization for I/O-bound operations. The asyncio library provides event loop mechanisms that enable handling thousands of concurrent connections with minimal memory overhead compared to thread-based approaches.
Asynchronous request handling using libraries like aiohttp or httpx enables Python applications to process multiple API requests simultaneously without blocking threads on I/O operations. This approach is particularly beneficial for applications that aggregate data from multiple external APIs or handle high volumes of concurrent user requests.
Database connection optimization through connection pooling and asynchronous database libraries like asyncpg significantly improves API performance for data-intensive applications. Proper connection pool configuration balances resource utilization with performance requirements, ensuring sufficient connections are available for peak loads while avoiding resource waste during low-traffic periods.
Caching strategies provide substantial performance improvements by reducing redundant computation and external service calls. Redis integration offers distributed caching capabilities that scale across multiple application instances, while in-memory caches like functools.lru_cache provide fast access to frequently used data within individual processes.
Monitoring and Observability Implementation
Comprehensive observability provides visibility into Python API behavior, performance characteristics, and potential issues before they impact users. Modern monitoring approaches collect metrics, logs, and traces across all application layers to create complete pictures of system health and performance.
Structured logging using libraries like structlog provides consistent, searchable log data that facilitates debugging and analysis. Log messages should include correlation IDs, request contexts, and relevant business information while avoiding sensitive data exposure. Proper log aggregation and analysis enable proactive issue identification and resolution.
Application Performance Monitoring tools provide detailed insights into request processing, database query performance, and external service dependencies. These tools help identify performance bottlenecks and optimize application behavior based on real-world usage patterns. Integration with alerting systems ensures prompt notification of performance degradation or error rate increases.
Distributed tracing becomes essential for microservices architectures where requests span multiple services. Python applications can implement tracing using libraries like OpenTelemetry that provide standardized instrumentation and correlation across service boundaries, enabling end-to-end request tracking and performance analysis.
What Is Real-Time API Architecture with Event-Driven Patterns?
Real-time API architecture represents a fundamental shift from traditional request-response patterns to continuous, event-driven communication that enables immediate data propagation and interactive user experiences. Modern applications increasingly demand real-time capabilities for collaborative features, live updates, and responsive user interfaces that reflect changes instantaneously across distributed systems.
Understanding WebSocket Implementation in Python
WebSockets provide full-duplex communication channels that enable both clients and servers to initiate data transmission at any time, creating persistent connections ideal for real-time applications. Python WebSocket implementations using libraries like websocket-client or framework-specific solutions like Django Channels enable sophisticated real-time features with manageable development complexity.
The WebSocket protocol upgrade process begins with standard HTTP requests that negotiate protocol switching with servers, establishing persistent connections that bypass traditional request-response limitations. Python servers can implement WebSocket handlers that manage connection lifecycles, message routing, and client authentication while maintaining high performance under concurrent connection loads.
Connection management becomes crucial in WebSocket applications as servers must track active clients, handle disconnections gracefully, and route messages efficiently among connected users. Python applications typically implement connection registries using data structures like dictionaries or sets that enable fast client lookup and message broadcasting operations.
Advanced WebSocket patterns include room-based messaging systems that group related clients and enable targeted message delivery to specific user segments. Python implementations can create subscription models where clients join topic-specific channels and receive updates relevant to their interests, reducing bandwidth usage and improving user experience through focused content delivery.
Server-Sent Events for Unidirectional Data Streaming
Server-Sent Events provide standardized mechanisms for streaming real-time updates from servers to web clients using standard HTTP connections. SSE implementations in Python frameworks like Flask or FastAPI enable streaming data delivery through generator functions that yield formatted event messages to connected clients.
The SSE protocol format includes event types, data payloads, and optional retry intervals that provide structured communication between servers and clients. Python applications can implement SSE endpoints that stream various types of updates including status changes, notifications, or live data feeds while maintaining connection stability through built-in reconnection mechanisms.
Browser-based SSE clients provide automatic reconnection handling and event type filtering that simplify client-side development compared to WebSocket implementations. Python SSE servers can leverage these built-in capabilities to create robust real-time features with minimal client-side complexity, making SSE particularly suitable for applications requiring unidirectional data streaming.
Advanced SSE implementations can include client subscription management, event filtering based on user preferences, and integration with backend event sources like database change streams or message queues. Python applications can create comprehensive real-time architectures that combine SSE for data streaming with traditional REST APIs for interactive operations.
Webhook Integration and Event-Driven Architecture
Webhooks transform traditional polling-based integrations into efficient event-driven communications by enabling external systems to push notifications when relevant events occur. Python applications can both consume webhooks from external services and provide webhook endpoints for other systems to register event callbacks.
Webhook implementation in Python involves creating secure endpoints that validate incoming requests, process event payloads, and trigger appropriate application responses. Security considerations include signature verification, request validation, and rate limiting to prevent abuse while ensuring legitimate webhook deliveries are processed correctly.
Event-driven architecture patterns using webhooks enable loose coupling between system components, allowing independent scaling and development of different service areas. Python applications can implement event routing systems that distribute webhook events to appropriate handlers based on event types, payload content, or business logic requirements.
Integration with message queue systems provides reliable webhook processing that handles temporary failures and ensures event delivery even when downstream systems are unavailable. Python applications can implement webhook receivers that queue events for asynchronous processing, providing resilience and scalability for high-volume event scenarios.
Hybrid API Architectures Combining Multiple Patterns
Modern Python applications benefit from hybrid architectures that combine REST APIs, WebSockets, Server-Sent Events, and webhook patterns to provide comprehensive functionality tailored to different use cases. This architectural approach leverages the strengths of each communication pattern while avoiding the complexity of forcing all interactions into unsuitable protocols.
Design decisions for hybrid architectures involve mapping communication patterns to specific use cases based on requirements for bidirectional communication, real-time responsiveness, and connection persistence. REST APIs handle traditional CRUD operations and one-time requests, while real-time protocols manage continuous updates and collaborative features.
Load balancing and scaling considerations for hybrid APIs require understanding how different protocols behave under load and designing infrastructure that supports various connection types. WebSocket connections require sticky sessions or sophisticated connection routing, while REST APIs can be scaled horizontally with standard load balancing techniques.
Monitoring and debugging hybrid architectures require comprehensive observability that captures metrics and traces across all communication protocols. Python applications need monitoring solutions that provide visibility into connection counts, message delivery rates, and protocol-specific performance characteristics to ensure optimal system operation.
How Can You Achieve API Resilience and Production Readiness?
Production-ready Python APIs require comprehensive resilience patterns that address the complexities of distributed systems, network failures, and operational requirements. Modern resilience approaches combine circuit breaker patterns, health monitoring, and sophisticated deployment strategies that ensure reliable service delivery under adverse conditions.
Comprehensive Health Monitoring and Service Discovery
Health monitoring in production Python APIs involves multiple layers of checks that verify different aspects of system functionality and readiness to handle production traffic. Liveness probes confirm that application processes are running and responsive, while readiness checks verify that all dependencies are available and the service is prepared to handle requests.
Deep health checks can verify business logic functionality and data consistency by performing actual operations against system components. Python implementations should balance comprehensive health verification with performance impact, ensuring that health checks provide meaningful status information without consuming excessive resources or affecting production performance.
Service discovery integration enables dynamic registration and discovery of API services in containerized and microservices environments. Python applications can implement service discovery using tools like Consul or cloud provider services that enable automatic service registration, health monitoring, and load balancer configuration updates based on service availability.
Monitoring integration with alerting systems provides proactive notification of health status changes and performance degradation. Python APIs should implement structured health reporting that integrates with monitoring platforms and enables automated response to common failure scenarios while providing detailed information for manual troubleshooting.
Advanced Caching and Performance Optimization
Production Python APIs require sophisticated caching strategies that improve performance while maintaining data consistency and freshness. Multi-layer caching approaches combine in-memory caches, distributed caches like Redis, and HTTP-level caching to maximize performance across different types of data and access patterns.
Cache invalidation strategies address the challenge of maintaining data consistency while maximizing cache effectiveness. Python applications can implement event-driven cache invalidation that removes or updates cached data when underlying sources change, ensuring users receive current information without sacrificing performance benefits.
Cache warming strategies proactively populate caches with frequently accessed data, reducing cache miss rates and improving response times for common requests. Python implementations can include background processes that update caches based on usage patterns, business schedules, or data update frequencies.
Connection pooling and resource management optimize database and external service interactions by reusing connections and managing resource lifecycles efficiently. Python applications should implement connection pools with appropriate sizing, timeout configuration, and health monitoring that balance resource utilization with performance requirements.
Security Hardening for Production Environments
Production API security requires comprehensive protection against common attack vectors while maintaining usability and performance characteristics. Security hardening involves implementing multiple layers of protection including network security, application security, and data protection measures.
Input validation and sanitization protect against injection attacks and data corruption by ensuring all incoming data meets expected formats and constraints. Python APIs should implement comprehensive validation using schema-based approaches that provide clear error messages while preventing malicious input from reaching application logic.
Authentication and authorization systems in production environments often involve integration with enterprise identity providers and sophisticated role-based access control. Python applications can implement OAuth 2.0, SAML, or other enterprise authentication standards while maintaining performance and user experience requirements.
Security monitoring and incident response capabilities detect and respond to potential threats including unusual access patterns, authentication failures, and data access anomalies. Python APIs should implement security logging and alerting that integrates with security information and event management systems while protecting user privacy.
Deployment and Infrastructure Automation
Container-based deployment strategies provide consistent, reproducible deployments across development, testing, and production environments. Python applications benefit from Docker containerization that includes all dependencies and configuration while optimizing image size and security through multi-stage builds and minimal base images.
Kubernetes orchestration enables sophisticated deployment patterns including rolling updates, blue-green deployments, and automatic scaling based on demand. Python APIs can leverage Kubernetes features like health checks, resource limits, and service mesh integration to ensure reliable operation and optimal resource utilization.
Infrastructure as code approaches using tools like Terraform or Pulumi enable version-controlled, reproducible infrastructure management. Python developers can define infrastructure requirements alongside application code, ensuring consistent deployment environments and simplifying disaster recovery procedures.
Continuous integration and deployment pipelines automate testing, security scanning, and deployment processes while maintaining quality gates and approval workflows. Python APIs benefit from automated pipelines that include unit testing, integration testing, security scanning, and performance validation before production deployment.
Observability and Incident Response
Comprehensive observability provides visibility into Python API behavior across metrics, logs, and traces that enable effective troubleshooting and performance optimization. Modern observability approaches collect data from all application layers and provide correlated views of system behavior during both normal operation and incident scenarios.
Distributed tracing enables end-to-end request tracking across microservices architectures, providing insights into request flows, performance bottlenecks, and failure points. Python applications can implement tracing using OpenTelemetry or similar standards that provide consistent instrumentation and correlation across service boundaries.
Alerting strategies balance sensitivity with noise reduction, ensuring critical issues trigger immediate notification without overwhelming operations teams with false alarms. Python APIs should implement intelligent alerting based on multiple metrics and trends rather than simple threshold-based approaches that can produce excessive noise.
Incident response procedures provide structured approaches to identifying, resolving, and learning from production issues. Python development teams should establish clear escalation procedures, communication protocols, and post-incident review processes that improve system resilience over time through continuous learning and improvement.
What Are Practical Examples of Using APIs with Python?
Understanding practical applications of Python API usage helps developers transition from theoretical knowledge to real-world implementation scenarios. Modern data engineering workflows rely heavily on API integrations for extracting, transforming, and loading data from diverse sources into analytical systems.
Platforms like Airbyte (open-source, with 600+ pre-built connectors) simplify API-based data integration by handling authentication, pagination, rate limiting, and error recovery automatically. Developers can also use PyAirbytefor code-first workflows that provide programmatic control over data integration pipelines while leveraging Airbyte's robust connector ecosystem.
Airbyte transforms how organizations approach data integration by solving the fundamental problem of effectively managing data across diverse enterprise environments. The platform's open-source foundation combined with enterprise-grade security enables organizations to leverage pre-built connectors while avoiding vendor lock-in, making it particularly valuable for companies transitioning from legacy ETL platforms to modern cloud-native architectures.
The PyAirbyte library enables Python developers to programmatically manage data integration workflows, providing direct access to Airbyte's connector ecosystem through familiar Python interfaces. This approach combines the flexibility of code-based data processing with the reliability and maintenance advantages of community-maintained connectors.
Modern data teams benefit from Airbyte's approach to API integration complexity, including automatic handling of authentication flows, rate limiting compliance, and error recovery mechanisms that would require significant custom development effort. The platform processes over 2 petabytes of data daily, demonstrating production-scale reliability for enterprise data integration requirements.
How Should You Store Response Data from Python APIs?
API responses are often JSON, but you can store them as JSON, CSV (after flattening nested structures), or in cloud object storage services like Amazon S3, depending on downstream requirements.
Effective data storage strategies for Python API responses depend on data volume, access patterns, and downstream processing requirements. JSON format preserves the original response structure and supports complex nested data relationships, making it ideal for applications requiring flexible data exploration and analysis.
CSV storage after JSON flattening provides compatibility with traditional analytical tools and databases that expect tabular data formats. Python libraries like pandas enable efficient JSON normalization and CSV export for responses containing nested objects or arrays, though this approach may lose some data relationship information.
Cloud object storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage provide scalable, cost-effective storage for large volumes of API response data. These platforms integrate well with modern data processing frameworks and enable efficient data lake architectures for long-term storage and batch processing workflows.
Database storage options include document databases like MongoDB for JSON data, relational databases for structured data, and time-series databases for API responses containing temporal data. The choice between storage options depends on query patterns, data consistency requirements, and integration with downstream analytical tools.
Frequently Asked Questions
1. What is the difference between synchronous and asynchronous Python API requests?
Synchronous Python requests block execution until a response is received, handling one request at a time. Asynchronous requests use concurrency (e.g., asyncio) to process multiple API calls simultaneously, improving performance for I/O-bound or high-concurrency tasks.
2. How do you handle API rate limits in Python applications?
Handle API rate limits in Python by monitoring returned rate-limit headers, implementing retries with exponential backoff, and spacing requests using token bucket or sliding window algorithms. Libraries like ratelimit or custom decorators can automate timing and quota management.
3. What are the best practices for securing API keys in Python projects?
Best practices for securing API keys in Python: store them in environment variables, avoid hardcoding, exclude from version control, use key management services for production, implement key rotation, and leverage libraries like python-dotenv for local development.
4. How do you test Python applications that consume external APIs?
API testing strategies include using mock libraries to simulate API responses during unit testing, creating test doubles for external dependencies, implementing contract testing to verify API compatibility, and using tools like VCR.py to record and replay API interactions. Comprehensive testing should cover both successful responses and various failure scenarios.
5. When should you choose REST APIs versus GraphQL in Python applications?
Choose REST for straightforward CRUD operations, caching, and predictable data needs. Opt for GraphQL when clients require flexible queries, efficient bandwidth usage, or complex relational data. Python frameworks like FastAPI support both, allowing hybrid implementations as needed.
.webp)