Enterprise Data Architecture: Trends & Strategies

✨ AI Generated Summary
Enterprise Data Architecture (EDA) is a comprehensive framework that standardizes data collection, storage, integration, and governance across organizations to enable scalable, secure, and real-time analytics. Modern EDA addresses challenges of traditional systems by supporting diverse data types, AI/ML integration, decentralized data ownership (data mesh), unified access (data fabric), and advanced security measures like zero-trust and encryption.
- Core components include flexible ingestion, polyglot storage, transformation, governance, and AI-driven management.
- Implementation requires strategic planning, phased technology adoption, and strong governance frameworks.
- Emerging trends involve AI-powered metadata management, edge computing, and preparation for quantum security.
- Tools like Airbyte simplify integration with extensive connectors, flexible deployment, and enterprise-grade security.
Modern businesses generate vast amounts of data from operational systems, transactions, and customer interactions. Managing and analyzing such data can improve decision-making and business planning. However, raw data is often distributed across many platforms, which makes gathering meaningful insights difficult.
To overcome this complexity, you can implement enterprise data architecture (EDA). It involves setting standard structures, models, and governance policies that promote smooth data flow across departments and business units.
Let's explore the details of enterprise data architecture to understand how you can implement it for your business.
What Is Enterprise Data Architecture and Why Does It Matter?
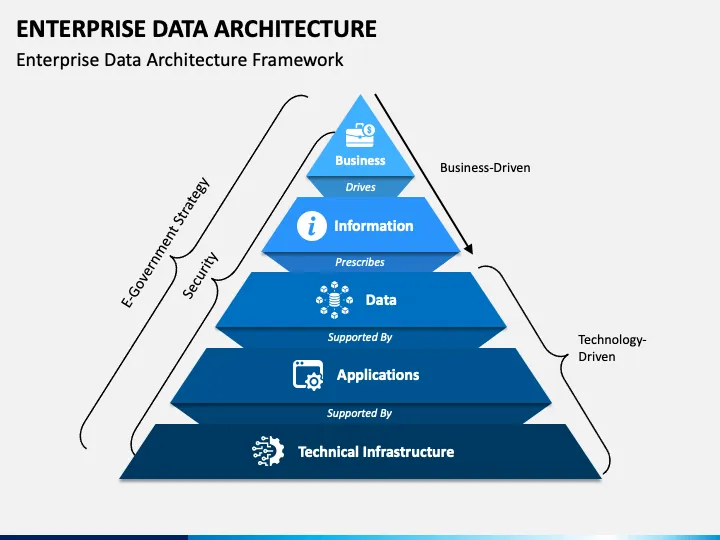
Enterprise data architecture (EDA) is a comprehensive framework that outlines the processes of data collection, storage, management, integration, and utilization across an entire organization. Modern enterprise data architecture has evolved beyond simple technology-first implementations to embrace business-driven approaches that prioritize organizational outcomes over technological convenience.
EDA provides a detailed view of data assets so your organization can maintain accurate and relevant data across diverse systems and platforms. You can gain valuable insights from structured, semi-structured, and unstructured data while making well-informed, data-driven decisions that support strategic objectives.
Modern implementations support multiple data-processing paradigms simultaneously, from traditional ETL to real-time streaming. EDA lets you align data strategies with business objectives, allowing you to use your data assets to their fullest potential.
Core Elements of Modern Enterprise Data Architecture
Modern data-architecture elements encompass governance, quality, security, storage, integration, and, increasingly, artificial-intelligence and machine-learning capabilities. The significance of robust enterprise data architecture cannot be overstated in today's digital economy.
Organizations generate and consume data at unprecedented scales. Contemporary EDA implementations must support both batch and streaming data-ingestion patterns while accommodating real-time analytics for operational decision-making and historical data-warehousing capabilities for comprehensive business intelligence.
What Challenges Do Enterprises Face With Traditional Data Architectures?
Traditional enterprise data architectures present numerous obstacles that prevent organizations from fully leveraging their data assets for competitive advantage and operational excellence.
Scalability and Performance Limitations
Legacy architectures struggle to handle the exponential growth in data volume, velocity, and variety that characterizes modern business environments. Traditional systems often require expensive hardware upgrades and extensive manual intervention to accommodate growing workloads.
These limitations create bottlenecks that restrict analytical capabilities and slow decision-making processes. Organizations find themselves constrained by infrastructure that cannot scale with business growth.
Complexity and Integration Challenges
Data exists across multiple formats including structured database records, semi-structured API responses, and unstructured documents, images, and sensor readings. Traditional architectures often lack the flexibility to handle this diversity efficiently.
Organizations require extensive custom development to manage data variety. This approach creates data silos that prevent comprehensive analysis and insights generation across the enterprise.
Limited Analytics and Insights Capabilities
Legacy systems typically focus on historical reporting rather than supporting the full spectrum of analytical requirements. This includes descriptive, diagnostic, predictive, and prescriptive analytics capabilities.
These limitations prevent organizations from implementing advanced use cases such as real-time fraud detection, dynamic pricing optimization, or predictive-maintenance programs. Business teams cannot access the analytical capabilities needed for competitive advantage.
Security and Governance Gaps
Traditional architectures often treat security and governance as afterthoughts rather than foundational design principles. This approach creates compliance risks and makes it difficult to implement comprehensive data-protection measures.
Organizations face increasingly complex regulatory requirements across multiple jurisdictions. Legacy systems struggle to provide the governance capabilities needed for modern compliance demands.
Vendor Lock-in and Technology Constraints
Many legacy platforms create dependencies on specific technologies or vendors, limiting organizational flexibility and increasing long-term costs. These constraints prevent organizations from adopting best-of-breed solutions.
Vendor dependencies make it difficult to adapt to changing business requirements or technological innovations. Organizations become trapped in technology ecosystems that may not serve their evolving needs.
Maintenance Overhead
Traditional data platforms often require significant engineering resources for ongoing maintenance. Organizations spend substantial portions of their data-engineering capacity on maintaining existing systems rather than creating new business value.
This maintenance burden limits innovation and prevents teams from focusing on strategic initiatives that drive competitive advantage.
What Are the Essential Components of Modern Enterprise Data Architecture?
Modern enterprise data architecture comprises several interconnected components that work together to create flexible, scalable, and efficient data-processing environments.
Data Sources and Ingestion Infrastructure
Contemporary data ingestion must handle diverse sources including internal operational systems, cloud-based SaaS applications, IoT devices, social-media feeds, and third-party APIs. Modern ingestion approaches support both batch processing for large historical datasets and real-time streaming for immediate processing requirements.
Advanced ingestion systems implement automated schema detection and evolution capabilities that adapt to changes in source data structures without requiring manual intervention. This automation significantly reduces maintenance overhead while ensuring data-pipeline reliability as business systems evolve.
Storage and Processing Layers
Modern storage architectures embrace polyglot approaches that leverage specialized storage systems optimized for specific use cases. Data lakes provide cost-effective storage for raw data in native formats, while data warehouses offer optimized query performance for structured analytical workloads.
Emerging data-lakehouse architectures combine the flexibility of lakes with the performance characteristics of warehouses. Processing layers incorporate multiple paradigms including traditional ETL pipelines, in-database ELT transformations that leverage the computational power of modern data warehouses, and streaming-processing engines that provide real-time-transformation capabilities.
Data Transformation and Modeling
Transformation capabilities encompass both code-based approaches using languages like SQL and Python, as well as low-code visual interfaces that enable business analysts to perform data-preparation tasks independently. Modern transformation frameworks support version control, testing, and collaborative-development practices that ensure data-pipeline quality and maintainability.
Data-modeling approaches include traditional dimensional modeling for business-intelligence use cases, as well as modern approaches such as data-vault modeling that provide greater flexibility for evolving business requirements.
Comprehensive Data-Governance Framework
Advanced governance encompasses not only traditional policies and procedures but also automated-enforcement mechanisms that ensure consistent application of data-quality rules, security policies, and compliance requirements across all data-processing activities. Modern governance frameworks support federated models that balance centralized standards with domain-specific autonomy.
What Are the Most Effective Enterprise Data Architecture Patterns?
Contemporary enterprise data architectures employ several sophisticated patterns that address different organizational requirements and use cases.
Data Mesh Architecture
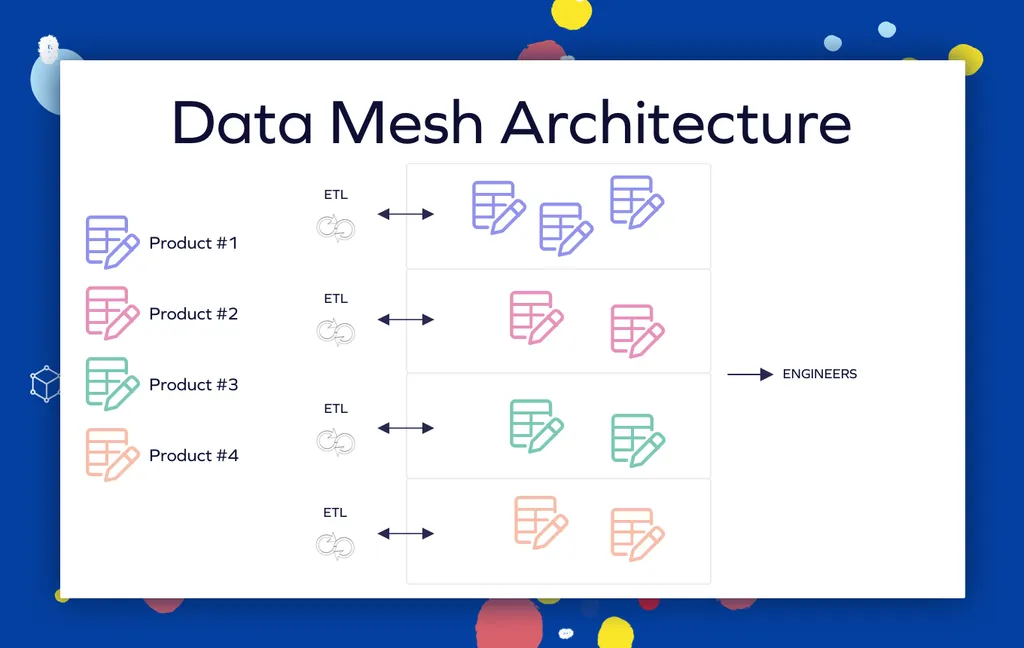
Data mesh represents a paradigm shift toward domain-oriented decentralized data ownership, where data is treated as a product owned by specific business domains rather than a centralized resource managed by IT teams. This approach enables domain teams to create, manage, and share data products according to their specific business requirements while maintaining enterprise-wide standards for interoperability and governance.
The data-mesh pattern requires sophisticated self-serve data-infrastructure platforms that enable domain teams to develop and maintain their data products autonomously. These platforms provide standardized tools and services for data ingestion, transformation, storage, and serving while ensuring that domain-specific data products remain discoverable, addressable, trustworthy, self-describing, and interoperable.
Implementation of data-mesh architectures involves establishing federated-governance models that combine enterprise-wide standards with domain-specific autonomy. This approach enables faster decision-making and greater flexibility in data-management practices while maintaining consistency and compliance across the organization.
Data Fabric Architecture
Data fabric provides a unified data-access layer across distributed and heterogeneous environments, creating seamless-integration capabilities that span on-premises and cloud systems. Unlike data mesh, which focuses on organizational patterns, data fabric emphasizes the technical infrastructure required to provide consistent data access regardless of physical location or storage format.
Data-fabric architectures leverage active-metadata management and artificial intelligence to automatically discover relationships across systems and orchestrate data flows. This automation reduces the manual effort required to maintain data integration while helping organizations avoid the complexity that typically accompanies distributed data environments.
Modern Data Lake and Warehouse Integration
Data lakes provide centralized repositories for storing vast amounts of structured, semi-structured, and unstructured data in native formats without requiring predefined schemas. Data warehouses continue to provide superior performance for well-defined analytical workloads. Lakehouse architectures combine the strengths of both approaches.
Lambda and Kappa Architecture Patterns
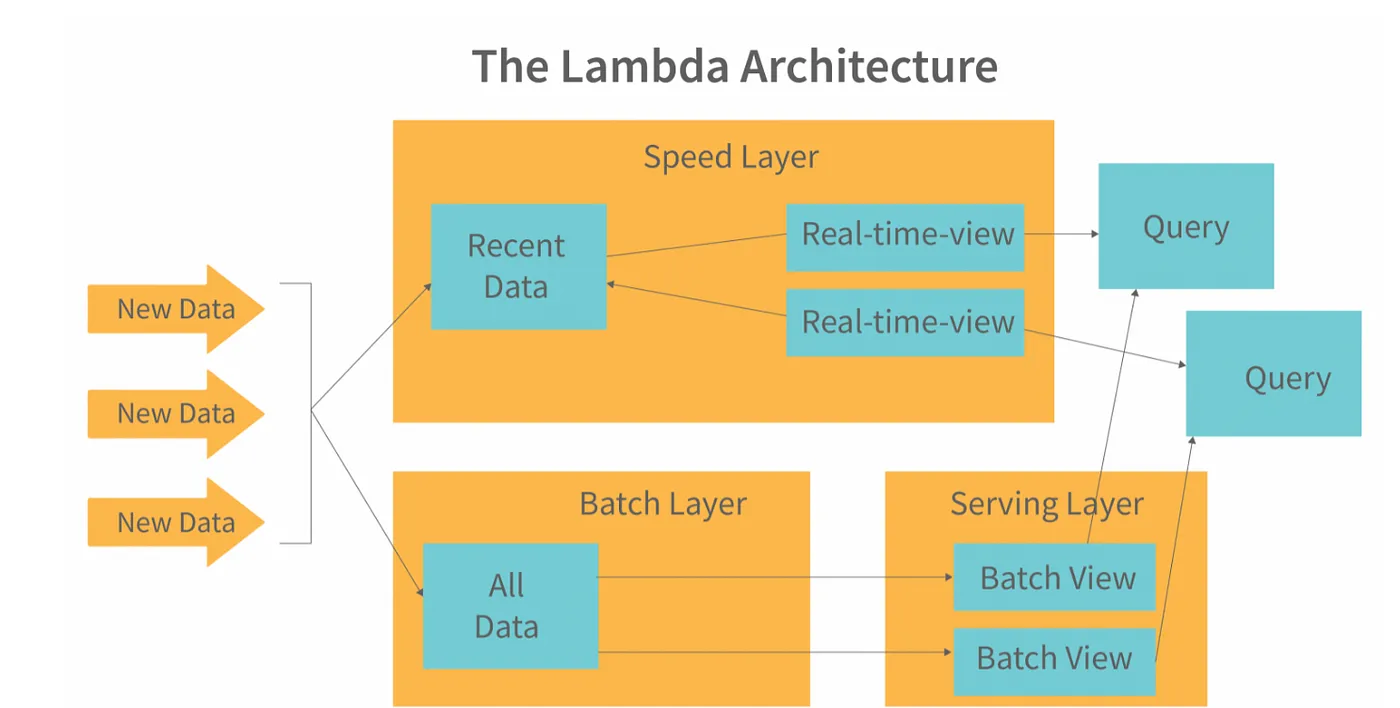
Lambda architecture implements parallel batch and speed layers to balance accuracy with low-latency insights. This pattern maintains separate processing paths for batch and real-time data, ensuring comprehensive coverage while meeting immediate analytical requirements.
Kappa architecture simplifies this approach by treating all data as a real-time stream processed by a single pipeline. This unified approach reduces complexity while maintaining the flexibility needed for modern analytical workloads.
How Does Security Work in Modern Enterprise Data Architecture?
Modern enterprise data-architecture security frameworks implement comprehensive protection measures throughout the entire data lifecycle rather than treating security as an add-on capability.
Zero-Trust Security Principles
Zero-trust approaches verify every request regardless of source location or previous authentication status. Every request is authenticated and authorized dynamically based on data attributes, user identity, device posture, and context.
This comprehensive verification ensures that security remains consistent across distributed environments. Organizations can maintain protection standards regardless of where data resides or how users access systems.
Comprehensive Data Encryption and Protection
Modern architectures implement encryption throughout the data lifecycle, covering data at rest and in transit. These implementations are supported by strong key-management systems, application-level encryption, and emerging techniques like searchable encryption.
Advanced protection mechanisms ensure that sensitive information remains secure even when accessed by authorized users. Organizations can maintain compliance requirements while enabling necessary business access to data resources.
Privacy-by-Design Implementation
Privacy safeguards including data minimization, anonymization, and consent management are built into architectures from the outset rather than retrofitted later. This approach ensures that privacy considerations influence every architectural decision and data-processing activity.
Organizations can proactively address privacy requirements while building systems that support business objectives and analytical requirements.
What Tools and Technologies Power Modern Enterprise Data Architecture?
Modern enterprise data architecture relies on sophisticated technology stacks that provide flexibility, scalability, and comprehensive capabilities across the data lifecycle.
Cloud-Native Platforms and Orchestration
Cloud-native data-processing platforms provide scalable infrastructure that adapts to changing workload requirements. Kubernetes orchestration enables consistent deployment and management across different environments while supporting hybrid and multi-cloud strategies.
These platforms offer the flexibility needed for modern data workloads while maintaining operational efficiency and cost effectiveness.
AI-Driven Management and Optimization
Advanced systems leverage artificial intelligence for metadata management, data-quality monitoring, and performance optimization. These capabilities reduce manual administrative overhead while improving system reliability and performance.
AI-driven approaches enable proactive identification and resolution of issues before they impact business operations or analytical capabilities.
Advanced Processing Tools
Modern architectures support both traditional ETL approaches and contemporary ELT patterns that leverage the computational power of cloud data platforms. Advanced tools support both batch and streaming workloads while providing the flexibility needed for diverse analytical requirements.
Processing capabilities extend across the entire data lifecycle, from initial ingestion through final consumption by business applications and analytical tools.
Specialized Storage Systems
Contemporary data architectures incorporate specialized storage engines including vector databases for AI applications and time-series databases for operational analytics. These specialized systems provide optimized performance for specific use cases while integrating seamlessly with broader data platforms.
How Do You Successfully Implement Enterprise Data Architecture?
Successful implementation requires careful planning, phased execution, and ongoing optimization to ensure that architectural investments deliver business value.
1. Strategic Planning and Requirements Analysis
Begin implementation by aligning architecture plans with business goals and conducting thorough assessments of current-state capabilities. Design future-state architectures that address identified gaps while building on existing investments and capabilities.
This planning phase establishes the foundation for successful implementation by ensuring that technical decisions support business objectives and operational requirements.
2. Technology Selection and Phased Implementation
Evaluate technology options based on specific organizational requirements including performance, scalability, security, and integration needs. Start implementation with high-impact use cases that demonstrate clear business value while building organizational confidence in the new architecture.
Manage change through comprehensive training programs and gradual transition approaches that minimize disruption to existing business operations.
3. Governance Framework Establishment
Define clear data stewardship roles and responsibilities while implementing automated quality controls that enforce standards consistently across all data-processing activities. Monitor system performance and business outcomes continuously to identify optimization opportunities and ensure ongoing value delivery.
Establish feedback loops that enable continuous improvement and adaptation to changing business requirements and technological capabilities.
How Does Modern Enterprise Data Architecture Support AI and Machine Learning Applications?
Contemporary enterprise data architectures provide specialized capabilities that enable organizations to implement sophisticated AI and machine learning applications effectively.
AI-Factory Architecture
Modern implementations orchestrate the complete AI lifecycle including data ingestion, feature engineering, model training, deployment, and monitoring. These comprehensive platforms ensure that AI initiatives have access to high-quality data while maintaining the governance and security requirements essential for enterprise applications.
AI-factory approaches streamline the development and deployment of machine learning models while ensuring that these capabilities integrate seamlessly with existing business processes and analytical workflows.
Semantic Layer Implementation
Advanced architectures include semantic layers that abstract technical database schemas into business concepts that can be consumed directly by AI systems. These abstractions enable more intuitive interaction between business users and AI capabilities while maintaining technical precision and accuracy.
Semantic layers facilitate the development of natural language interfaces and business-friendly AI applications that require minimal technical expertise to use effectively.
Vector Database Integration
Modern architectures incorporate specialized vector databases that store and query embeddings needed for semantic search and retrieval-augmented generation applications. These capabilities enable sophisticated AI applications including document search, recommendation systems, and conversational interfaces.
Vector database integration ensures that AI applications have access to the specialized storage and query capabilities needed for high-performance semantic operations.
What Are Key Considerations for Real-Time Data Processing?
Real-time data processing capabilities are essential for modern enterprise architectures that support operational decision-making and immediate response to business events.
Stream Processing and Event-Driven Design
Stream processing frameworks such as Apache Kafka and Apache Flink enable low-latency analytics and immediate response to business events. Event-driven architectures ensure that systems can respond to changing conditions without requiring batch processing delays.
These capabilities enable organizations to implement real-time fraud detection, dynamic pricing, and other time-sensitive applications that provide competitive advantage.
Edge Computing Integration
Edge computing brings computation closer to data sources, reducing latency and enabling faster insights for location-sensitive applications. This distributed approach ensures that critical decisions can be made immediately without requiring round-trip communication to centralized systems.
Edge integration is particularly valuable for IoT applications, mobile systems, and geographically distributed operations that require immediate response capabilities.
Scalability and Performance Optimization
Real-time systems require horizontal scaling capabilities, sophisticated load balancing, built-in redundancy, and proactive monitoring to ensure consistent performance under varying load conditions. These capabilities ensure that real-time processing remains reliable even during peak business periods.
Performance optimization includes both infrastructure scaling and application-level optimizations that ensure efficient resource utilization while maintaining response-time requirements.
How Can Airbyte Simplify Your Enterprise Data Architecture Implementation?
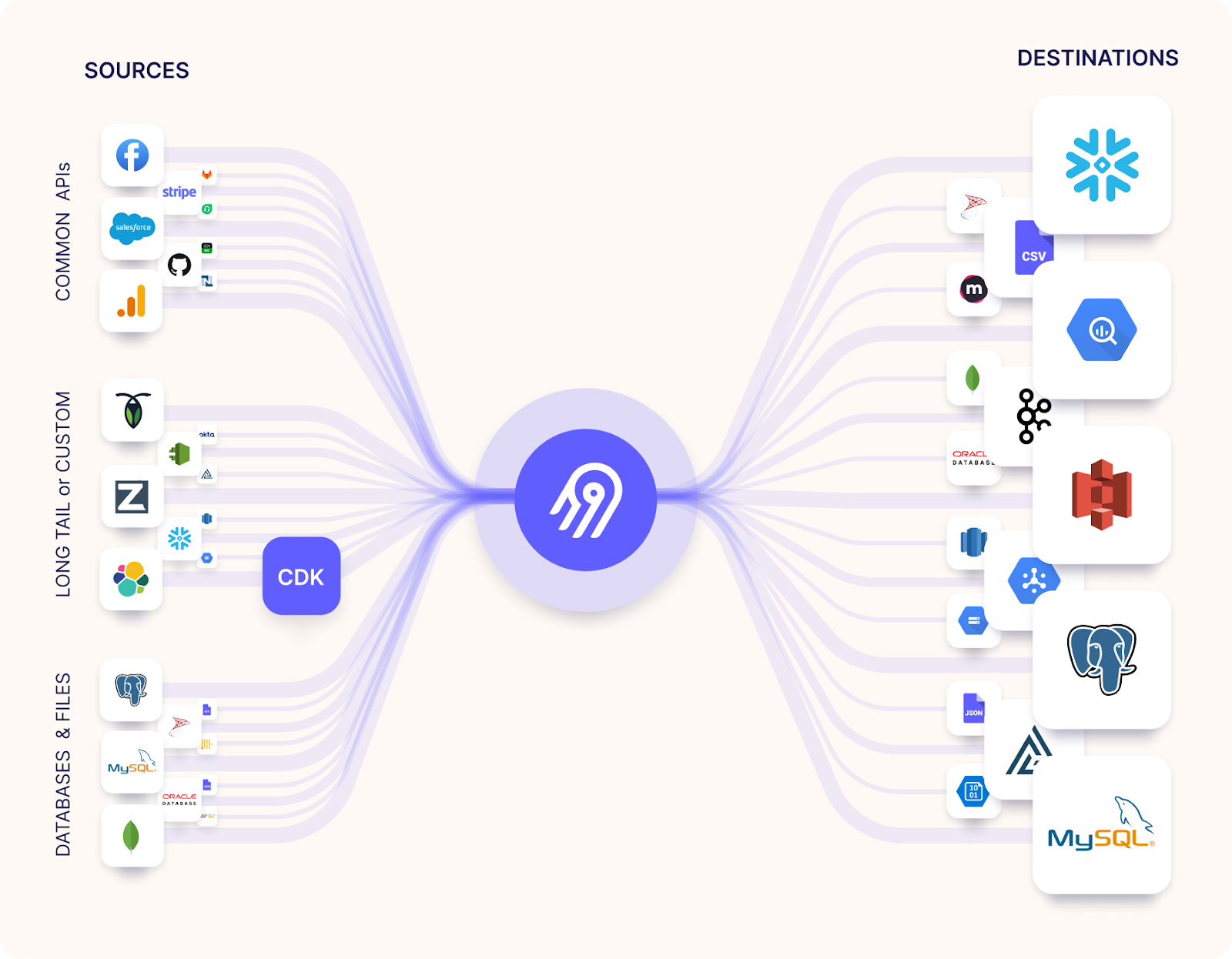
Airbyte provides comprehensive data integration capabilities that address the complex requirements of modern enterprise data architectures while maintaining the flexibility and control that organizations need.
Extensive Connector Library and Rapid Development
Airbyte offers an open-source platform with 600+ pre-built connectors and an AI assistant for rapid new-connector creation. This extensive library eliminates the development overhead typically associated with custom integration projects while providing the flexibility to create specialized connectors for unique business requirements.
The platform's connector development kit enables rapid creation of custom integrations without extensive engineering resources, significantly reducing time-to-deployment for new data sources.
Flexible Deployment Options
Organizations can deploy Airbyte in cloud, hybrid, or on-premises environments without vendor lock-in constraints. This flexibility ensures that deployment decisions can be based on business requirements including data sovereignty, security policies, and existing infrastructure investments rather than vendor limitations.
Deployment flexibility enables organizations to maintain control over their data architecture while leveraging modern integration capabilities across diverse technical environments.
Enterprise-Grade Security and Compliance
Airbyte maintains enterprise-grade security standards including SOC 2 Type II and ISO 27001 certifications while providing comprehensive support for change data capture and modern transformation tools like dbt. These capabilities ensure that data integration maintains enterprise security requirements while supporting advanced analytical use cases.
The platform's predictable capacity-based pricing model is particularly well-suited for scaling AI workloads where traditional per-row pricing approaches can become prohibitively expensive as data volumes grow.
What Emerging Trends Are Shaping the Future of Enterprise Data Architecture?
Several technological developments are driving significant evolution in enterprise data architecture approaches and capabilities.
AI and Active Metadata Management
Artificial intelligence is enabling self-optimizing, self-healing data stacks that can automatically detect and resolve issues, optimize performance, and adapt to changing requirements without manual intervention. These capabilities reduce operational overhead while improving system reliability and performance.
Active metadata management uses AI to automatically maintain data catalogs, detect quality issues, and recommend optimizations based on usage patterns and performance characteristics.
Edge Computing and Distributed Analytics
Edge computing capabilities are enabling distributed analytics with localized intelligence that can respond to immediate conditions without requiring centralized processing. This distributed approach is particularly valuable for IoT applications, mobile systems, and geographically distributed operations.
Distributed analytics ensure that organizations can leverage data insights at the point of business activity while maintaining centralized governance and coordination capabilities.
Quantum Computing and Post-Quantum Security
Organizations are beginning to prepare cryptography and data processing models for quantum computing advances that will fundamentally change computational capabilities and security requirements. Post-quantum security approaches ensure that current investments in data architecture remain secure as quantum computing capabilities mature.
These preparations include evaluating quantum-resistant encryption methods and considering how quantum computing capabilities might enable new forms of data processing and analysis.
Conclusion
Enterprise data architecture continues evolving rapidly as organizations balance increasing data complexity with growing demands for real-time insights and AI-powered applications. Success requires careful planning, flexible implementation approaches, and ongoing adaptation to technological and business changes. Organizations that invest in modern, flexible architectures while maintaining strong governance and security practices will be best positioned to leverage data as a competitive advantage in the digital economy.
Frequently Asked Questions
What is the difference between data architecture and enterprise data architecture?
Data architecture usually covers a single system or domain, whereas enterprise data architecture spans the entire organization, focusing on integration, governance, and standardization across all data domains.
How long does it typically take to implement enterprise data architecture?
Timelines vary, but phased roll-outs often deliver initial value in a few months, with comprehensive modernization taking longer periods and ongoing optimization thereafter.
What factors should influence cloud vs. on-premises deployment decisions?
Consider data-sovereignty rules, existing investments, cost profiles, scalability needs, and internal expertise. Many organizations adopt hybrid models that balance these requirements.
How do you measure success in enterprise data architecture?
Track technical KPIs like availability, data-quality scores, and pipeline latency alongside business metrics including time-to-insight, cost savings, and revenue impact from data-driven initiatives.
What skills and organizational changes are required?
Organizations need cloud platforms, data-engineering, and analytics expertise combined with robust governance frameworks, cross-functional collaboration capabilities, and a culture that prioritizes data-driven decision-making.
.webp)