How to Create a Database Schema in PostgreSQL: An Ultimate Guide

✨ AI Generated Summary
PostgreSQL schemas organize and isolate database objects within a database, enabling efficient data management, security, and multi-tenant support. Key practices include consistent naming conventions, schema-level access control, and integration with CI/CD pipelines using tools like Flyway or pgroll for zero-downtime migrations. Platforms like Airbyte enhance schema management by providing schema-aware data replication and automated change capture, ensuring scalable and secure data architectures.
PostgreSQL stands out as one of the most versatile database systems available today, powering everything from startup applications to Fortune 500 enterprise systems. Yet many data professionals struggle with a fundamental challenge: managing database schemas that can evolve safely without breaking production systems or requiring costly downtime. This reality becomes even more complex when organizations need to coordinate schema changes across development teams, maintain data integrity during migrations, and integrate schema management into modern CI/CD workflows.
A PostgreSQL schema serves as the architectural foundation that determines how your data is organized, accessed, and maintained throughout your application's lifecycle. Understanding how to create, manage, and evolve schemas effectively can mean the difference between a database that scales gracefully and one that becomes a bottleneck constraining business growth. This comprehensive guide explores PostgreSQL schema fundamentals while examining modern tools and techniques that enable zero-downtime migrations and automated schema management workflows.
TL;DR: PostgreSQL Schemas at a Glance
- PostgreSQL schemas are logical containers within a database that organize tables, views, functions, and other objects—providing namespace isolation and security boundaries.
- Schemas enable user isolation, efficient data organization, and prevention of naming collisions, making them essential for multi-tenant applications and complex databases.
- Zero-downtime migrations use tools like pgroll and Reshape to apply schema changes progressively through expansion, synchronization, and contraction phases.
- CI/CD integration requires version-controlled DDL, migration tools like Flyway, ephemeral test instances, and automated schema linting for reliable deployments.
- Airbyte provides schema-aware CDC and data movement capabilities to maintain consistency across distributed data architectures as schemas evolve.
What Are PostgreSQL Schemas and How Do They Function Within Your Database?
In an object-relational DBMS like PostgreSQL, a schema is defined as a logical container that holds database objects such as tables, indexes, views, operators, data types, sequences, and functions. Within a single PostgreSQL database, you can have one or more schemas. Each schema provides a way to manage and isolate database objects, making it easier to organize large and complex databases.
By default, you can only access objects in schemas you own. To allow access to other schemas, the owner must grant the USAGE privilege. Additionally, creating objects in another schema requires the CREATE privilege on that schema.
Why Do Schemas Matter in PostgreSQL Development and Data Management?
PostgreSQL schemas provide essential organizational and security benefits that become increasingly important as your database grows in complexity. Understanding these advantages helps you design better database architectures from the start.
Core Benefits of Schema Organization
User Isolation enables multiple users to access the same database without interfering with each other's data or objects. This separation becomes crucial in multi-tenant applications where different clients need isolated data spaces.
Efficient Data Organization allows you to logically group database objects to manage and navigate complex databases. Rather than having hundreds of tables in a single namespace, you can organize them by functional area or business domain.
Avoiding Object Name Collisions becomes essential when third-party applications store their objects in separate schemas to prevent naming conflicts. This prevents issues where different applications might want to use the same table names.
Security and Development Advantages
Improved Security comes from assigning permissions at the schema level for granular control. You can grant specific users access to entire functional areas without managing individual object permissions.
Streamlined Development allows teams to work in their own schema to develop and test features without affecting production. This isolation reduces the risk of accidental data corruption during development cycles.
What Should You Know Before Creating PostgreSQL Schemas?
Understanding PostgreSQL's schema hierarchy and naming conventions ensures you build well-organized, maintainable database structures. These foundational concepts guide all subsequent schema management decisions.
PostgreSQL Schema Hierarchy
The PostgreSQL schema hierarchy refers to the structural organization of database objects within PostgreSQL. Following this hierarchy helps you manage database objects efficiently, ensure accessibility, and maintain data separation.
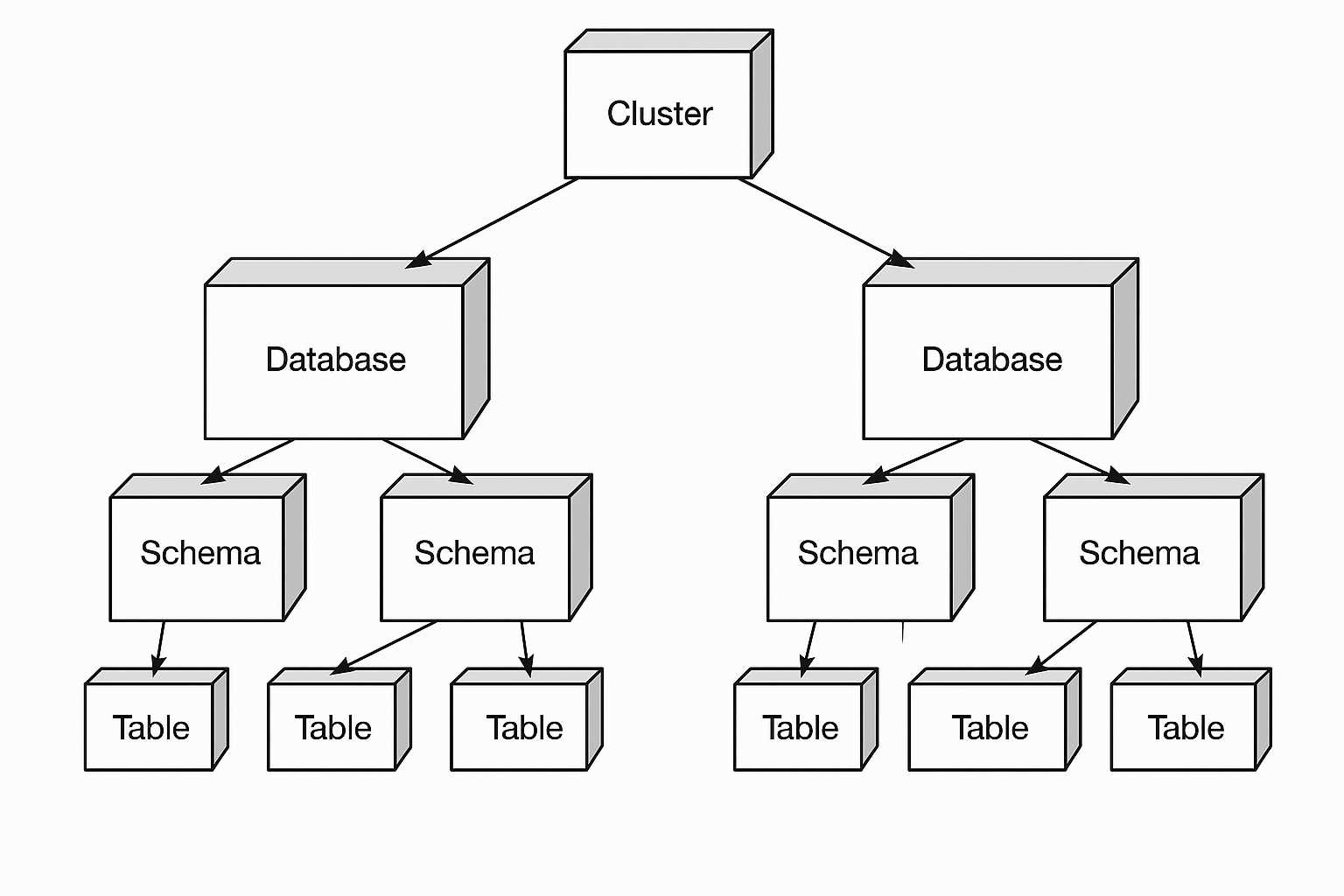
1. Cluster Level Organization
The highest level consists of multiple named databases managed by a single PostgreSQL server instance. This cluster approach allows you to separate completely different applications or environments on the same server infrastructure.
2. Database Level Structure
A collection of schemas for different types of database objects. You access data in a specific database by connecting to it. Each database maintains its own set of schemas and cannot directly access objects in other databases on the same cluster.
3. Schema Level Components
A namespace within a database that allows you to organize and group related objects including tables, views, functions, sequences, indexes, and triggers. This level provides the primary organizational structure for your database objects.
Understanding the PostgreSQL Public Schema
The public schema is created automatically in every PostgreSQL database. Objects created without specifying a schema are stored here by default. For production environments, create separate schemas for better organization rather than relying solely on the public schema.
Schema Naming Conventions
Effective schema naming follows several important principles. Use descriptive names that clearly indicate the schema's purpose, such as users or inventory. Avoid reserved keywords like select, table, or user which can cause parsing conflicts.
PostgreSQL converts unquoted identifiers to lowercase, so maintain consistency by using lowercase letters throughout your naming convention. For multiple words, use underscores as separators, such as user_data or order_processing.
Consider using prefixes for grouping related schemas, such as sales_orders and sales_payments. This approach makes it easier to identify related functional areas when viewing schema lists.
Schema Search Path Configuration
The search path determines the order in which PostgreSQL looks for objects referenced without a schema qualifier. This mechanism allows you to reference tables and other objects without always specifying the full schema name.
How Can You Create Database Schema in PostgreSQL?
Creating schemas in PostgreSQL requires understanding both the basic syntax and the various options available for schema configuration. This process forms the foundation for organizing your database objects effectively.
Prerequisites for Schema Creation
Download and install PostgreSQL on your system. Ensure you have appropriate privileges to create schemas in your target database. You need either superuser privileges or the CREATE privilege on the specific database where you want to create schemas.
1. Establish Database Connection
Launch pgAdmin or open a terminal for psql command-line access. Connect to your PostgreSQL server using appropriate credentials and specify the target database.
2. Use Basic Schema Creation Syntax
Define a new schema using the CREATE SCHEMA command with various options for ownership and initial objects. The basic syntax provides flexibility for different schema configuration needs.

3. Implement Advanced Schema Creation Patterns
Create schemas with specific ownership and initial database objects in a single transaction. This approach ensures consistent schema setup across different environments.
4. Verify Schema Creation Success
After creating your schema, verify it exists and has the correct ownership and permissions. Use system catalogs to check schema properties and ensure proper configuration.
How Do You Implement Zero-Downtime PostgreSQL Schema Migrations?
Modern production environments demand schema changes that don't interrupt business operations. Zero-downtime migration tools have emerged as essential components for teams managing PostgreSQL at scale.
Advanced Migration Framework Architecture
Tools like pgroll maintain backwards compatibility by creating dual schema versions that coexist temporarily. This approach ensures applications can continue operating while schema changes are applied progressively.
The typical zero-downtime migration process follows three phases. Expansion adds new schema elements alongside existing ones without removing anything. Data Synchronization keeps old and new structures consistent using triggers or logical replication. Contraction removes deprecated elements after all applications successfully migrate to the new schema version.
Tools such as pg_osc create shadow tables and perform atomic swaps, avoiding long-lasting ACCESS EXCLUSIVE locks that would block application access except for a very brief period during the final swap. This technique is particularly valuable for large table modifications that would otherwise require extended downtime windows.
Implementing Reversible Schema Changes
Frameworks like pgroll store migration definitions in JSON files and use internal state tracking to enable instant rollbacks when issues are detected. Versioned views expose multiple schema versions so different services can transition independently without coordination requirements.
Reshape offers a Rust-based approach to atomic, reversible migrations with built-in integrity validation. These tools automatically generate the reverse operations needed to safely roll back changes when problems occur during deployment.
Managing Complex Schema Evolution Patterns
Dependency-aware planning maintains referential integrity across related schema changes. The migration system analyzes object dependencies and applies changes in the correct order to prevent constraint violations.
Column renames are typically handled by introducing the new column alongside the old one, performing a backfill, and updating application code to use the new column before finally removing the old column. This process allows for a gradual migration without downtime.
While tools and features can help automate some partition management tasks, schema changes to partitioned tables in PostgreSQL generally require explicit intervention for each partition.
What Are the Best Practices for PostgreSQL Schema CI/CD Integration?
Integrating schema management into continuous integration and deployment pipelines requires careful planning and the right tooling. Modern DevOps practices demand automated, repeatable schema deployment processes.
Database-as-Code Strategies
Version control all DDL alongside application code to maintain consistency between schema and application changes. This approach ensures schema modifications are reviewed, tested, and deployed using the same processes as application code.
Use tools like Flyway and Liquidbase or sequential, checksummed migrations that track applied changes and prevent duplicate applications. These tools provide rollback capabilities and maintain detailed migration histories.
Spin up ephemeral PostgreSQL instances in CI to run migrations on every pull request. This testing approach catches migration issues before they reach production environments and validates that migrations work correctly with realistic data volumes.
Advanced Pipeline Components
Schema linters catch anti-patterns early in the development process by analyzing proposed schema changes for performance impacts, security issues, and naming convention violations. These automated checks prevent problematic changes from reaching production.
Environment-sync tools detect drift between development, staging, and production environments by comparing actual schema structures against expected configurations. This monitoring helps identify unauthorized changes and configuration inconsistencies.
Automated rollback tests significantly increase confidence in reversibility by applying migrations forward and backward in test environments. This validation helps ensure that rollback procedures are likely to work correctly when production issues require rapid schema reversion.
Security and Governance Automation
Automated privilege scans detect overly broad permissions by analyzing schema-level and object-level access grants. These scans help maintain the principle of least privilege across database environments.
Compliance policies enforce encryption requirements and audit trail configurations through automated checks. These policies ensure that sensitive data handling meets regulatory requirements without manual verification processes.
Performance impact analysis compares query plans before and after migrations to identify potential performance regressions. This analysis helps prevent schema changes that inadvertently slow down critical application queries.
How Do You Work With PostgreSQL Schemas After Creation?
Schema management extends beyond initial creation to include ongoing maintenance, modification, and organization tasks. Understanding these operations ensures you can effectively manage schemas throughout their lifecycle.
Modifying Schema Properties
Rename schemas when organizational needs change or when correcting naming conventions. Schema renaming affects all contained objects but doesn't require rebuilding the objects themselves.
Change schema ownership when team responsibilities shift or when implementing new security policies. Owner changes affect who can create objects in the schema and who can grant access to others.
Removing Schemas Safely
Drop schemas carefully using CASCADE and RESTRICT options to control the scope of removal. Understanding these options prevents accidental data loss and helps maintain referential integrity.
CASCADE removes all contained objects including tables, views, functions, and their data. RESTRICT is the default behavior that blocks schema removal if any objects exist, providing a safety mechanism against accidental deletions.
Moving Objects Between Schemas
Transfer database objects between schemas to reorganize logical groupings or implement new security boundaries. This capability allows you to restructure databases without rebuilding objects from scratch.
Moving objects updates their fully qualified names but preserves all data, indexes, and constraints. Applications referencing these objects may need updates if they use unqualified names or specific search paths.
What Are the Best Practices for Creating PostgreSQL Schemas?
Effective schema creation follows established patterns that improve maintainability, security, and performance. These practices prevent common pitfalls and establish foundations for scalable database architectures.
Establish Consistent Naming Standards
Adopt a consistent naming convention across all schemas in your organization. Document these standards and enforce them through code reviews and automated linting tools. Consistent naming makes databases easier to navigate and reduces confusion among team members.
Create separate schemas for each user or application rather than dumping everything in the public schema. This separation provides better security boundaries and makes it easier to manage permissions and track object ownership.
Implement Proper Access Control
Keep detailed records of which roles own which schemas and what permissions have been granted. This documentation becomes essential for security audits and troubleshooting access issues.
Grant privileges at the schema level rather than individual objects when possible. Schema-level permissions are easier to manage and provide consistent access patterns for related objects.
Limit the search path to required schemas only. Overly broad search paths can create security vulnerabilities and make it harder to predict which objects will be accessed by unqualified names.
Ensure Deployment Reliability
Use IF NOT EXISTS in idempotent scripts that can be run multiple times safely. This approach prevents errors when scripts are accidentally executed multiple times during deployment processes.
Periodically review and clean up unused schemas to maintain database hygiene. Document the purpose of each schema and establish sunset procedures for schemas that are no longer needed.
Prefer RESTRICT when dropping schemas and use CASCADE only when you're certain about the scope of impact. This conservative approach prevents accidental data loss during cleanup operations.
How Can Airbyte Enhance Your PostgreSQL Schema Management?

Airbyte provides sophisticated PostgreSQL integration capabilities that extend beyond basic connectivity to include schema-aware data movement and transformation. These features help organizations manage complex schema evolution scenarios across distributed data architectures.
Schema-Aware Change Data Capture
Airbyte's CDC leverages logical replication slots to propagate data changes (inserts, updates, deletes) in real time across connected systems. Schema modifications in source PostgreSQL databases typically require manual updates or separate schema management processes to be reflected in downstream systems.
The platform monitors data changes through PostgreSQL's logical replication infrastructure and captures schema (structural) modifications through periodic schema polling, maintaining consistency across your entire data ecosystem when schemas evolve.
Automated Schema Evolution Management
Custom components or manual configuration in Airbyte can address column additions, type changes, and constraint updates, allowing alignment with your organization's data governance policies and transformation requirements, but these are not handled automatically by configurable rules across connected systems.
The system provides flexible deployment options including cloud-native, hybrid, and on-premises deployments while maintaining consistent schema management capabilities across all environments. This flexibility ensures that schema evolution processes work regardless of your infrastructure choices.
Enterprise Integration Capabilities
Enterprise-grade security ensures that replication respects PostgreSQL RBAC policies and governance requirements. Airbyte maintains the security boundaries and access controls established in your source databases throughout the data movement process.
The platform includes 600+ pre-built connectors and a no-code AI-Assistant for custom connectors, enabling integration with virtually any system that interacts with your PostgreSQL schemas.
PyAirbyte allows developers to integrate connectors directly into Python workflows, providing programmatic access to schema-aware data movement capabilities within existing development environments.
Conclusion
A well-designed PostgreSQL schema is essential for efficiently organizing data and enabling scalable database architectures. Modern tooling including zero-downtime migration frameworks like pgroll, robust CI/CD pipelines, and schema-aware replication platforms like Airbyte elevates schema management from a risky, manual process to a competitive advantage. Organizations adopting these practices report reduced deployment risk, faster development cycles, and improved operational efficiency. PostgreSQL's flexible schema system, combined with contemporary automation tools, provides the foundation for data architectures that grow with business needs rather than constraining them.
Frequently Asked Questions
What Is the Difference Between a PostgreSQL Database and Schema?
A PostgreSQL database is a collection of schemas, whereas a schema is a namespace within the database holding tables, views, functions, and other objects. Multiple schemas in one database organize related objects and manage access control.
How Do You List All Schemas in a PostgreSQL Database?
You can list all schemas using the command \dn in psql or by querying the information schema: SELECT schema\_name FROM information\_schema.schemata;. This shows both system schemas like pg catalog and user-created schemas. You can also use pg_namespace system catalog for more detailed schema information.
Can You Move Tables Between Schemas Without Losing Data?
Yes, you can move tables between schemas using the ALTER TABLE command: ALTER TABLE current_schema.table_name SET SCHEMA new_schema;. This operation preserves all data, indexes, constraints, and triggers while changing the table's logical location. However, applications using unqualified table names may need search path updates.
What Happens to Permissions When You Drop a Schema?
When you drop a schema with CASCADE, all permissions granted on the schema and its contained objects are automatically revoked. Users who previously had access to schema objects will lose that access. It's important to document and plan for permission changes before dropping schemas in production environments.
How Do You Back Up Individual PostgreSQL Schemas?
Use pg_dump with the --schema option to back up individual schemas: pg_dump --schema=schema_name database_name > backup.sql. You can specify multiple schemas or exclude specific ones using --exclude-schema. This approach provides granular backup control for complex databases with multiple logical divisions.
.webp)